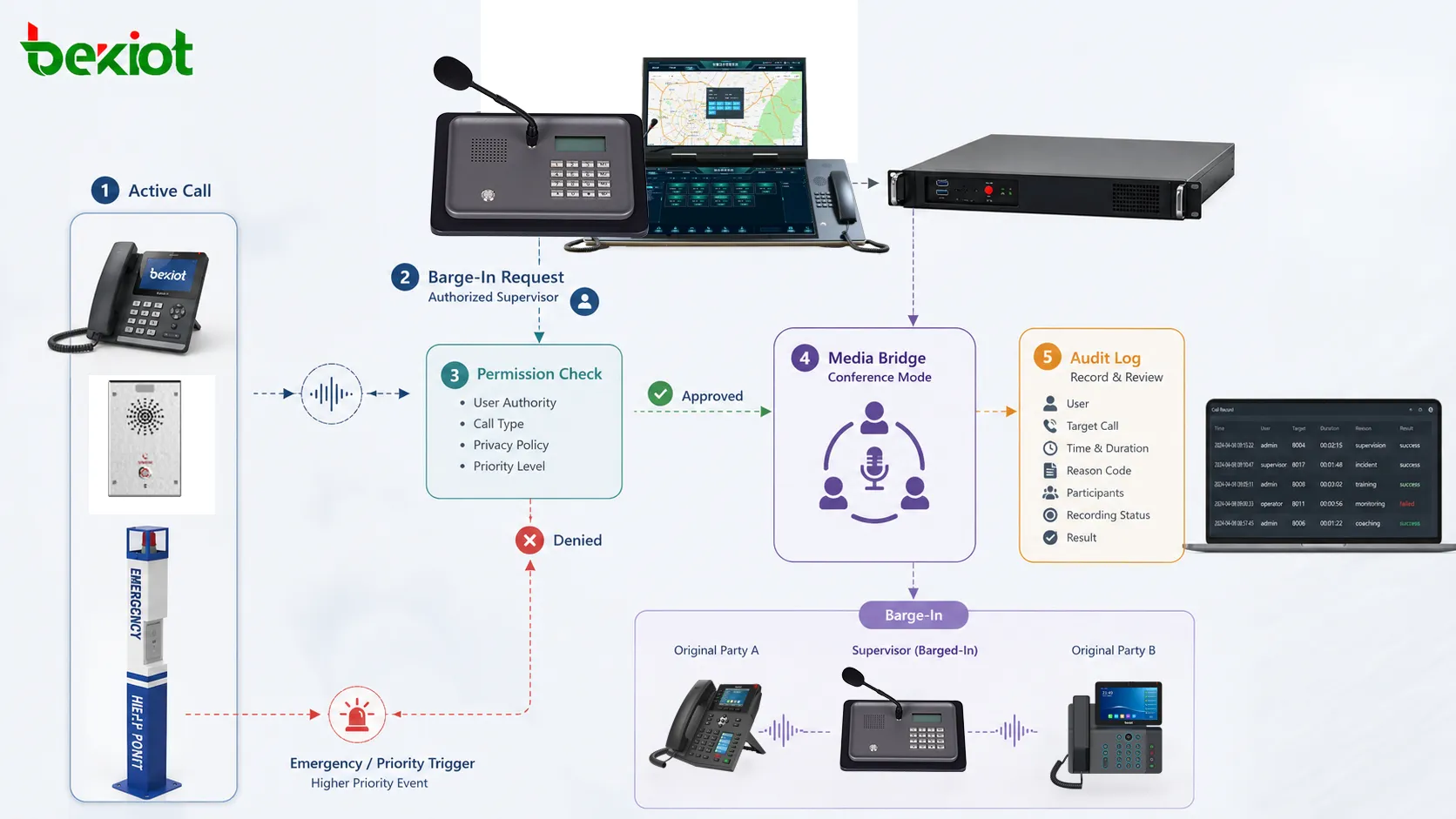
システムアップグレードは、アップグレードパッケージから始めるべきではありません。まず確認すべきなのは、変更中に何を安定させ続ける必要があるのかという運用上の問いです。新しいバージョンは、セキュリティ修正、性能向上、新機能、より長いサポート期間をもたらす一方で、互換性問題、設定変更、サービス停止、復旧負荷を生む可能性もあります。
したがって、良いアップグレード管理とは、適切なタイミングで「更新」を押すことではありません。サービス、ユーザー、データ、事業継続を守る形で変更を制御することです。
変更理由から始める
最初のルールは、なぜアップグレードが必要なのかを確認することです。セキュリティ脆弱性、重大な不具合、コンプライアンス、サポート終了のリスクを修正するために急ぐものもあれば、性能改善、機能追加、新しいハードウェア対応、将来の構成に合わせるために計画されるものもあります。任意の更新は、十分なテスト時間を確保できるまで待つべきです。
理由が曖昧なままだと、判断は反応的になりやすくなります。新しい版が出た、ベンダーが推奨した、別部門が実施したというだけで更新すると、不要なリスクを増やします。安定しているシステムは、効果が明確でない限り不用意に変更すべきではありません。
アップグレードの目的は実務的な言葉で書く必要があります。たとえば「認証脆弱性を修正する」「新しいデータベース版に対応する」「通話処理能力を高める」「サポート切れのOSを置き換える」「新しいプラットフォーム連携を有効にする」などです。目的が明確なら、テスト範囲と受け入れ基準を決めやすくなります。
理由が明確になれば、緊急度も判断できます。重大なセキュリティ更新は短い承認サイクルを必要とし、機能更新は低リスクの保守時間に配置でき、主要な構成変更は段階的な導入が必要になることがあります。理由ごとに管理レベルは異なります。
技術作業の前に業務影響を確認する
アップグレードは技術システムだけに影響するものではありません。ユーザー、サービス時間、連携アプリケーション、レポート、アクセス権、端末、顧客体験、生産フロー、サポート体制に影響する場合があります。技術作業の前に、そのシステムに依存する業務プロセスを特定する必要があります。
これは、通信基盤、データベース、産業システム、顧客ポータル、決済システム、監視基盤、社内運用ツールのように継続稼働するシステムで特に重要です。短時間の停止でも、着信漏れ、取引失敗、生産遅延、記録欠落、利用者からの苦情につながることがあります。
影響確認では、利用ピーク、重要ユーザー群、外部顧客、社内部門、サービスレベル、法規制やコンプライアンス要件を含めます。緊急対応、生産制御、セキュリティ監視、公共サービスを支えるシステムでは、一般的な事務ツールより厳格な計画が必要です。
この確認結果はスケジュールを決める根拠になります。通常の保守時間に実施できるものもあれば、夜間や週末が必要なもの、臨時のバックアップシステム、ユーザー通知、段階切替が必要なものもあります。技術的に簡単でも、時期を誤ると高リスクになります。
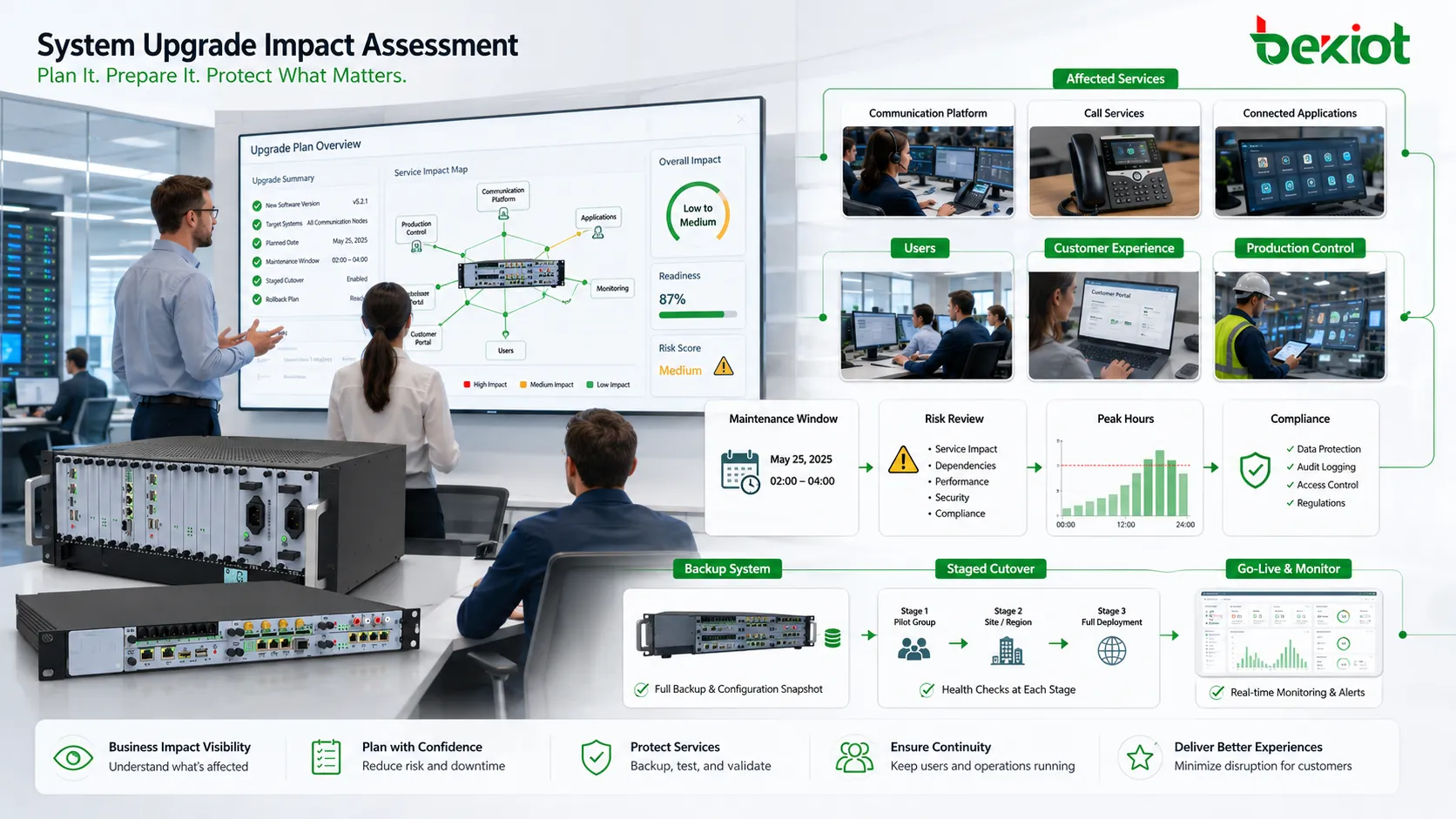
正確なインベントリを先に作成する
何が接続されているか分からないシステムは安全に更新できません。インベントリには、サーバー、OS、データベース、ミドルウェア、アプリケーション、端末、ネットワーク機器、ストレージ、ライセンス、証明書、API、外部連携、バックアップツール、監視システム、ユーザーのアクセス方法を含めます。
この一覧は隠れた依存関係を見つける助けになります。レポートツールが特定のデータベース版に依存している、古いクライアントが新しいプロトコルを扱えない、ファームウェア変更後に機器が動かない、セキュリティシステムが古いAPIを使っている、といった問題は珍しくありません。導入後に発見されるとロールバック圧力が高まります。
設定インベントリも同じくらい重要です。システムパラメータ、ルーティングルール、ユーザー権限、連携キー、スケジュールジョブ、サービスアカウント、ファイアウォールルール、証明書、カスタムスクリプトを更新前に記録します。失敗の多くは新バージョンではなく、設定の欠落や上書きから発生します。
大規模環境では、拠点やノードごとのバージョン差も把握します。支店ごとにパッチレベルが異なる、サーバーに独自モジュールがある、機器モデルごとに特別なファームウェア経路が必要、という差は更新順序とテスト設計に影響します。
互換性は想定せず確認する
互換性は最も一般的なアップグレードリスクの一つです。新バージョンは、より新しいデータベース、別のランタイム、更新されたブラウザ、変更されたドライバ、改訂されたAPI、新しい認証方式を要求することがあります。接続先が互換でなければ、インストールは成功しても運用は失敗します。
互換性確認では、ハードウェア、OS、データベース、アプリケーション版、プロトコル、インターフェース、ブラウザ、モバイルクライアント、端末、ドライバ、プラグイン、証明書、外部サービスを確認します。一般的なリリースノートだけに頼らず、現場条件をベンダー要件とローカル設定に照らし合わせます。
後方互換性も重要です。古いクライアント、機器、連携を更新後も使い続ける必要があるなら、直接テストします。一定期間だけ混在版を許可するシステムもあれば、全コンポーネントを同時に更新する必要があるものもあります。この判断を誤ると部分的なサービス障害になります。
互換性が不明な場合は、パイロット環境を使います。本番に触れる前に、代表的な機器、ユーザー役割、データフロー、インターフェース呼び出しを検証できます。これにより、保守時間中に重大な衝突を発見する可能性を下げられます。
| アップグレード領域 | 重要なルール | 確認理由 |
|---|---|---|
| アプリケーション版 | リリースノートと依存関係の変更を確認 | 機能喪失とインターフェース衝突を防ぐ |
| データベース | スキーマ、ドライバ、移行要件を確認 | データアクセスと取引安定性を保護する |
| OS | ランタイム、サービス、セキュリティポリシー対応を確認 | サービス起動と権限問題を避ける |
| ネットワークとセキュリティ | ファイアウォール、証明書、DNS、アクセスルールを確認 | 切替後の接続失敗を防ぐ |
| 端末とクライアント | 代表的な機器とバージョンをテスト | 現場の互換性苦情を減らす |
環境を変える前にデータを保護する
データ保護は譲れないルールです。更新前に、バックアップの有無、完全性、復元方法、保存場所、保持方針、復旧時間を確認します。検証されていないバックアップは、復旧計画ではなく仮定にすぎません。
データベースやアプリケーション基盤では、正しい時点でバックアップを取得する必要があります。更新中もデータが変化するなら、書き込み停止、トランザクションログ利用、スナップショット取得、レプリケーション復旧のどれを使うか決めます。方法は構成と許容停止時間によって異なります。
設定バックアップも無視できません。アプリ設定、サービスファイル、ルーティング表、スケジュールタスク、ユーザー役割、証明書、鍵、カスタムテンプレートは、業務データと同じくらい重要な場合があります。失敗後に手作業で再構築すると、ソフトウェア復元より時間がかかることがあります。
データ移行スクリプトも慎重に確認します。一部の更新は、スキーマ、インデックス、文字コード、フィールド長、データ構造を変更します。これらは戻しにくい場合があります。移行が可逆か、ロールバックに完全復元が必要か、復旧にどれだけ時間がかかるかを把握します。
実環境に近いテスト環境を使う
テストは重要な点で本番に近い場合に価値があります。小さく空のテストシステムはインストーラが動くことを確認できても、性能問題、データ移行問題、連携失敗、権限衝突、機器互換性を見つけられないことがあります。
テスト環境には、代表的なデータ、ユーザー役割、接続サービス、設定、インターフェース呼び出し、典型的な負荷を含めます。完全な本番コピーでなくても、主要リスクを表面化させるだけの現実性が必要です。
テストケースは実際の業務フローに沿わせます。システム種別に応じて、ログイン、記録作成、レポート出力、取引実行、アラーム発生、API呼び出し、ファイル生成、モバイル利用、接続機器利用を行います。技術的な起動成功はサービス準備完了ではありません。
必要に応じて性能テストも行います。新バージョンは1ユーザーでは正常でも、実負荷で遅くなる場合があります。データベース移行、キャッシュ、メモリ、CPU、ディスクI/O、ネットワーク遅延、バックグラウンドジョブを確認します。評価はインストール完了ではなく運用挙動で行います。

導入前にロールバックを準備する
ロールバックを考えずにアップグレードを進めてはいけません。ロールバックとは、失敗や許容できない問題が発生したときに、前の正常状態へ戻すことです。「必要ならバックアップを戻す」だけでは不十分で、具体的な手順を知っている必要があります。
ロールバック計画では、誰が判断するか、どの条件で実行するか、どのファイルやデータベースを復元するか、復旧にかかる時間、失われる可能性のあるデータ、ユーザーへの通知方法を定義します。データ移行後に戻せるのか、前進修復しか現実的でないのかも明確にします。
簡単に戻せる更新もあれば、データベース構造、暗号方式、ファームウェア、設定形式を変えて戻しにくくする更新もあります。この場合は、段階導入、ブルーグリーン構成、予備ノード、並行運用でリスクを下げます。
可能ならロールバックもテストします。訓練していない計画は緊急時に失敗することがあります。部分的な演習でも、権限不足、復元速度の遅さ、不完全なバックアップ、責任分担の曖昧さを発見できます。
保守ウィンドウを管理する
保守ウィンドウは、アップグレードを実行する予定時間です。ユーザー影響、システム負荷、担当者の可用性、ベンダー支援、バックアップ完了、ロールバック時間を考慮して選びます。よくある誤りは、更新時間だけを見積もり、障害対応やロールバック時間を含めないことです。
保守ウィンドウには、準備、最終バックアップ、更新実行、検証、必要な修正、ロールバック判断、ロールバック実行、ユーザー連絡を含めます。更新に1時間、戻しに3時間かかるなら、計画はその現実を反映する必要があります。
更新前には変更凍結が必要なことがあります。同じ時間帯に、他チームが無関係な設定変更、ネットワーク変更、データベース変更、アクセス方針変更を行うべきではありません。複数の変更が重なると原因特定が難しくなります。
サポート体制も重要です。主要技術者、アプリ担当、ネットワーク技術者、DB管理者、セキュリティチーム、ベンダーサポートに連絡できる状態が必要です。重要な依存関係を理解している唯一の人が不在の時に更新を予定してはいけません。
変更前後にユーザーへ連絡する
ユーザー連絡は混乱を防ぎます。更新前に、対象ユーザーへ予定時間、サービス影響、一時的な制限、連絡先、保守時間中に避ける操作を知らせます。公開向けシステムでは、顧客への通知も必要になることがあります。
通知内容は具体的であるべきですが、技術詳細を詰め込みすぎないようにします。ユーザーは、システムが使えないか、データ入力を止めるべきか、モバイルクライアント更新が必要か、パスワードやログイン方法が変わるか、いつ復旧するかを知る必要があります。
更新後は、システムが利用可能になったことを通知します。機能が変わった場合は、短いリリースノートや利用案内が必要です。問題が残る場合は、既知の制限と解決予定を説明します。
良いコミュニケーションは不要な問い合わせを減らします。更新後の苦情の多くは技術障害ではなく、画面変更、ログイン要求、セッション切れ、一時的な性能変化に利用者が驚くことで発生します。
受け入れ確認で結果を検証する
インストーラが終わってもアップグレードは完了ではありません。システムが受け入れ確認を通過して初めて完了です。これらの確認は更新前に定義し、何をもって「成功」とするのかを明確にしておきます。
受け入れ確認には、サービス起動、ログイン、主要フロー実行、データの読み書き、レポート生成、インターフェース呼び出し、機器接続、スケジュールタスク、権限確認、バックアップ動作、監視状態、ユーザー確認を含めることがあります。正確な項目はシステム機能により異なります。
重要機能を先に確認します。業務取引を扱うなら取引を、通信を扱うなら通話経路やメッセージフローを、監視を扱うならアラーム受信とダッシュボード更新を、データベースを提供するならアプリ接続とクエリを確認します。重要サービスが未確認のうちに細かな機能へ時間を使うべきではありません。
ログ確認も受け入れの一部です。エラーログ、警告、失敗ジョブ、認証エラー、データベース移行メッセージ、連携失敗は、ユーザーが気付く前に問題を示すことがあります。画面が正常に見えても、更新が完全に正常とは限りません。

リリース後もシステムを監視する
アップグレード後の最初の数時間から数日は重要です。実トラフィック、スケジュールジョブ、ピーク利用、特定のユーザー行動で初めて出る問題があります。特に重要システムでは、通常運用より積極的に監視します。
監視対象は、CPU、メモリ、ディスク、データベース性能、ネットワーク通信、サービス状態、エラーログ、ユーザーセッション、取引成功率、API応答、キュー長、ストレージ増加などです。ユーザーのフィードバックも確認します。利用者がダッシュボードより先に問題に気付く場合があります。
性能ベースラインは有用です。更新前の通常応答時間、リソース使用量、エラー率を知っていれば、新バージョンをより客観的に比較できます。ベースラインがないと、遅さが新しい問題なのか以前からのものなのか判断しにくくなります。
監視期間は明確に決めます。小規模システムなら数時間で十分な場合もありますが、重要システムでは数日間または一つの業務サイクルを通す必要があります。通常条件で安定が確認されるまで、アップグレードを閉じるべきではありません。
変更内容を記録する
文書化はアップグレードの一部であり、任意の事務作業ではありません。導入したバージョン、変更した設定、取得したバックアップ、発生した問題、解決方法、承認者、残作業を記録します。
バージョン記録は特に重要です。将来の障害対応では、現在動いているシステム版、データベース版、ファームウェア版、ドライバ版、パッチレベルを知る必要があります。記録がなければ、後続チームは環境を再調査することになります。
既知の問題も記録します。ある機能に後続調整が必要、ある連携にベンダー確認が必要、あるユーザー群に再教育が必要といった項目は、非公式チャットに残すだけでなくアップグレード記録に含めます。
良い文書化は次の更新も改善します。何がうまくいったか、どこに時間がかかったか、どのリスクを見落としたか、どの手順を改善すべきかを振り返れます。各アップグレードは、次の変更に向けた準備を高める機会です。
まとめ
システムアップグレードで最も重要なルールは、変更を制御することです。成功するアップグレードは、データを保護し、互換性を検証し、停止時間を抑え、ロールバックを準備し、ユーザーへ連絡し、リリース後のサービス挙動を確認します。アップグレードパッケージはプロセスの一部にすぎません。
業務上重要な環境では、アップグレードを一つの運用フローとして扱うのが安全です。影響を評価し、実態に近いテストを行い、慎重にスケジュールし、責任を明確にして実行し、結果を確認し、リリース後に監視します。これらのルールを守ることで、更新は避けられる中断ではなくシステム改善の手段になります。
FAQ
新バージョンが出たらすべてのシステムをすぐ更新すべきですか?
いいえ。緊急のセキュリティ修正は迅速な対応が必要な場合がありますが、機能更新やメジャーバージョン変更は先に評価すべきです。導入前に互換性、業務影響、テスト準備、ロールバック方法を確認します。
アップグレード前で最も重要な準備は何ですか?
最も重要なのは復旧可能性の確認です。検証済みバックアップ、設定記録、ロールバック手順、明確な判断ルールが含まれます。復旧に確信がなければ、単純な更新でもリスクになります。
テスト後でもアップグレードが失敗するのはなぜですか?
テストが、本番の高負荷、特殊なデータ、古いクライアント、外部連携、スケジュールジョブ、権限差、ネットワーク制限を見落とすことがあります。テスト環境は重要な本番依存関係を反映する必要があります。
アップグレード後の監視はどれくらい続けるべきですか?
システムの重要度と利用サイクルによります。小さな社内ツールなら短時間で十分な場合がありますが、重要サービスではピーク時間、スケジュールタスク、業務サイクル全体を通して監視する必要があります。
アップグレード記録には何を含めるべきですか?
旧版と新版、更新時刻、担当者、バックアップ詳細、変更設定、テスト結果、発見した問題、ロールバック状態、ユーザー通知、後続対応を含めます。