

遠隔拠点が中央プラットフォームとの接続を失っても、現場の担当者は互いに通話し、緊急連絡先へ連絡し、必要な通信を維持しなければならない場合があります。
ローカルサバイバビリティの価値はここにあります。これは理想的なネットワーク状態のためではなく、主経路が途切れ、WANリンクが不安定になり、中央サーバーに到達できず、拠点からクラウドサービスへアクセスできない時のために設計されます。
ネットワーク分離中も重要通信を維持する
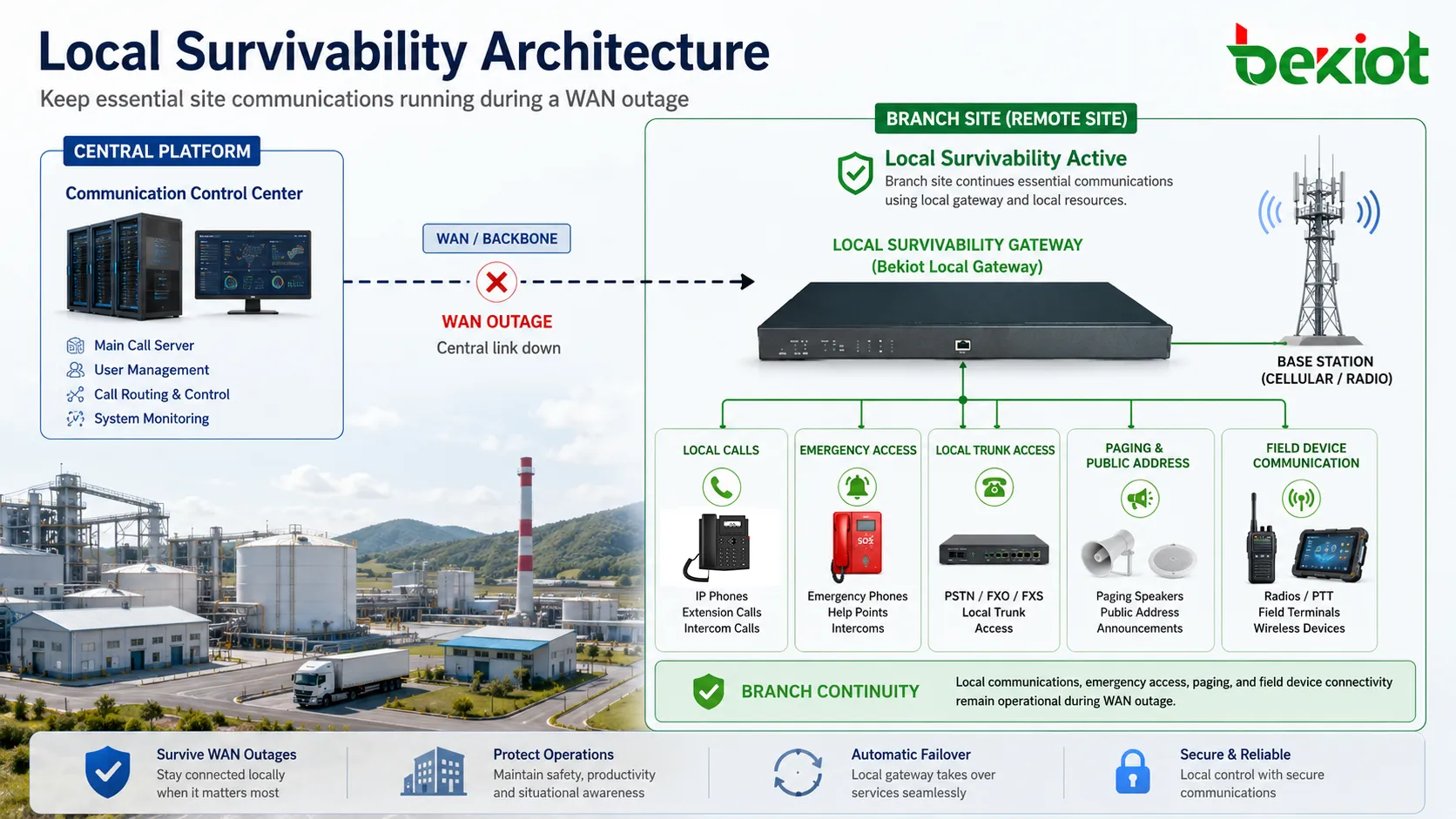
ローカルサバイバビリティとは、支店、現場ステーション、産業施設、遠隔通信ノードが中央システムとの接続を失っても、核心となるサービスを継続できる能力を指します。通信ネットワークでは、ローカルユーザー同士の通話、事前定義された緊急番号への接続、ローカルトランクの利用、重要な音声サービスの維持を、中央プラットフォームの復旧を待たずに行えることを意味します。
実務上の利点は継続性です。多くの分散システムは、登録、ルーティング、ポリシー制御、録音、ユーザー管理を中央サーバーに依存しています。この集中型モデルは通常運用では効率的ですが、依存点も作ります。WANリンクが故障すると、遠隔拠点の端末は主呼制御サーバー、クラウドPBX、ディスパッチ基盤、通信制御センターへアクセスできなくなる可能性があります。サバイバビリティがなければ、拠点は運用上孤立します。
ローカルサバイバビリティがあれば、ローカルゲートウェイ、サーバー、コントローラー、組み込みサービスノードが一時的に一部の通信機能を引き継げます。中央プラットフォームを完全に置き換える必要はありません。内部通話、緊急通信、ローカルルーティング、フェイルオーバートランク、端末登録のフォールバック、限定的な指令や放送機能など、現場運用に必要な機能を保持します。
この能力は、工場、交通駅、エネルギー施設、キャンパス、物流拠点、鉱山、トンネル、空港、公共サービス拠点で特に重要です。こうした環境では、幹線リンクが停止しただけで通信を止めることはできません。ローカルサバイバビリティは、完全なサービス停止ではなく、制御されたフォールバック状態を提供します。
単一の中央プラットフォームへの依存を下げる
集中型通信プラットフォームは管理を簡素化しますが、遠隔拠点にローカルフォールバックがなければ単一の依存点になります。通常の構成では、端末登録、呼ルーティング、認証、番号変換、サービス方針が中央システムで処理されます。すべての通信動作がその基盤を通る必要がある場合、リンク障害は同じ建物内の単純なローカル通話にまで影響します。
ローカルサバイバビリティは、この依存モデルを変えます。定義された条件下で、選択されたローカル機能を利用可能に保てます。たとえば、内線はサバイバブルゲートウェイへ再登録でき、ゲートウェイはローカル通話用のダイヤル計画をキャッシュできます。緊急番号はローカルトランクへルーティングできます。警備室、保守チーム、生産制御室、現場端末は、主サーバーに到達できない場合でも拠点内で通信を続けられます。
これはすべてを分散化するという意味ではありません。良い設計では、通常時は統一設定、監視、ポリシー制御、保守性を得るために集中管理を使います。サバイバビリティは第二の運用状態を追加するものです。ネットワークが正常な時は中央で動作し、中央経路が失敗した時だけローカル制御へ移行します。
利点はバランスです。組織は集中型構成の効率を得ながら、ネットワーク分離時の全面的なサービス喪失を避けられます。これは、各支店、駅、工場、現場ノードが独自の運用責任を持つ多拠点展開で特に価値があります。
主経路が故障しても緊急通話を維持する
緊急通話はローカルサバイバビリティを導入する最も重要な理由の一つです。多くの現場では、ネットワーク接続を乱す事故の最中に、警備、消防、医療支援、制御室、地域の緊急サービスへ連絡する必要が出ます。通信システムが中央基盤だけに依存していると、最も必要な瞬間に緊急通話が失敗する恐れがあります。
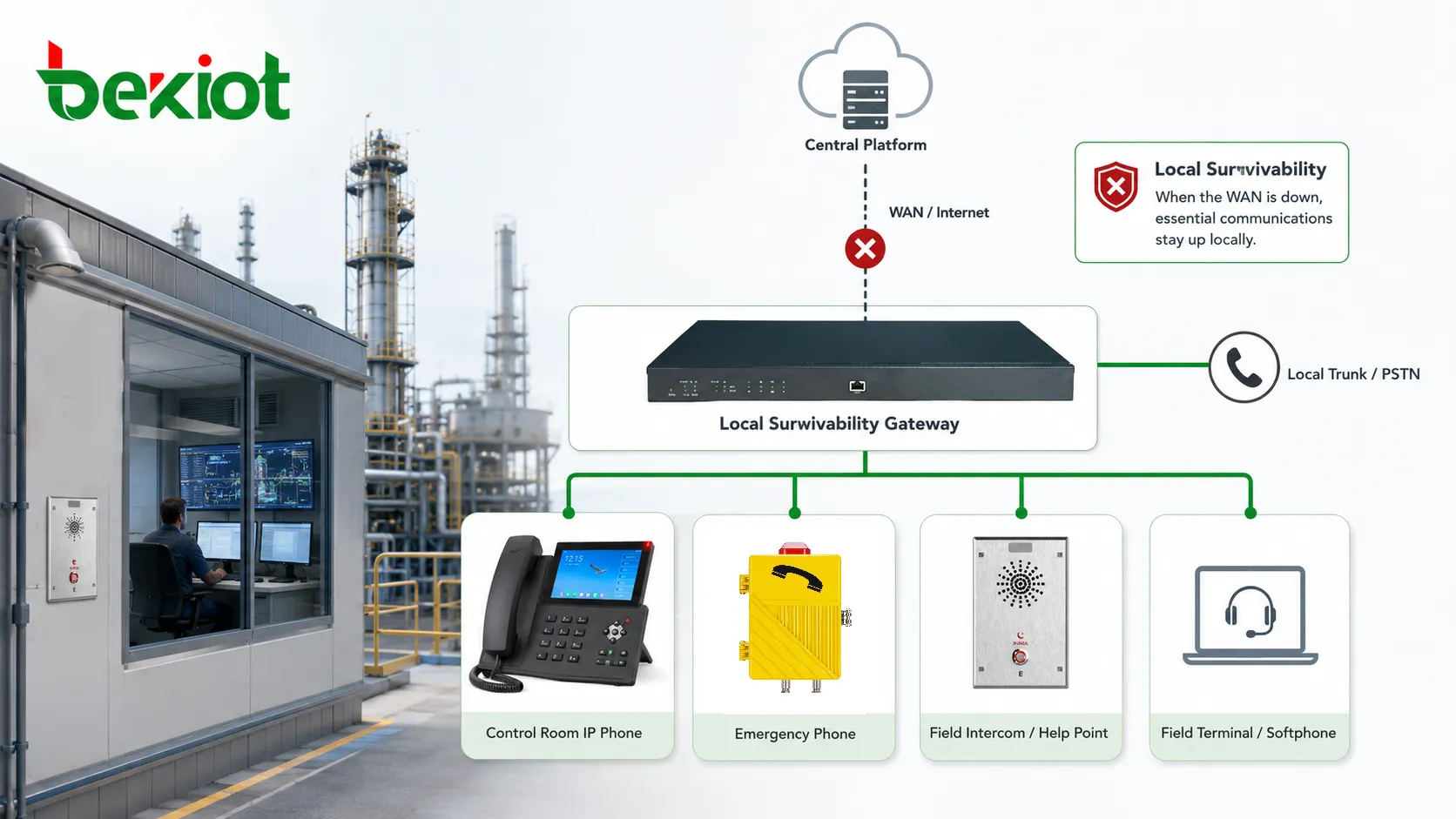
サバイバブルなローカルノードは、ローカル番号、アナログ回線、SIPトランク、無線ゲートウェイ、事前定義された応答端末を使って緊急ルーティングを維持できます。具体的な設計は現場により異なりますが、原則は同じです。緊急通信には、遠隔インフラに完全依存しないローカル経路が必要です。遠隔産業施設、交通駅、地下施設、海上プラットフォーム、公共安全分野では特に重要です。
ローカルサバイバビリティは、故障時の緊急動作を予測しやすくします。中央プラットフォームが停止した時、ユーザーがどの番号が使えるかを推測するべきではありません。利用可能な緊急番号、呼の転送先、オペレーターへの通知方法、フォールバックルーティングが自動かどうかを明確に定義する必要があります。通常時だけ動く複雑な仕組みより、障害時に明確に動く仕組みの方が重要です。
導入計画では、緊急ルーティングを通常通話とは別にテストすべきです。WAN障害を模擬した時に緊急通話が接続されるか、必要に応じて発信位置や端末IDが保持されるか、ローカル担当者が着信を受けるか、バックアップトランクが正しく動作するかを確認します。実際の事故前に経路が検証されていて初めて、サバイバビリティは意味を持ちます。
産業現場と遠隔拠点のローカル運用を支える
中央ネットワークが使えないだけで運用を止められない現場があります。生産ラインでは制御室と現場作業者の連携が必要です。鉄道駅ではホーム、警備、保守の内部通信が必要です。鉱山では地下ポイントと現地監督の音声連絡が必要です。変電所では運転員と技術者の通信が必要です。これらはローカルな業務フローであり、中央から切り離されても維持されるべきものです。
ローカルサバイバビリティは、必要とする人と機器の近くで通信を維持することでこれを支えます。すべての通話を遠隔データセンターやクラウドへ送るのではなく、選択されたローカル通話を拠点内で処理できます。これにより長いネットワーク経路への依存が減り、劣化状態でも基本的な運用能力が残ります。
産業環境での価値は技術的な継続性だけではありません。安全と生産規律も支えます。運転員は故障を報告でき、保守チームは修理を調整でき、警備は門や巡回ポイントと連絡でき、緊急電話は現地応答先へ到達できます。拠点は縮退運用になるかもしれませんが、通信が完全に沈黙するわけではありません。
WANの修復に時間がかかる場所では特に有効です。遠隔拠点、屋外盤、地下経路、リース回線はすぐに復旧するとは限りません。ローカルサバイバビリティ層は修理チームに時間を与え、必要な内部連携を維持します。
ネットワーク全体を複雑にせずレジリエンスを高める
レジリエンスというと、二重サーバー、二重リンク、バックアップデータセンター、複数キャリア、並列システムのような完全冗長を想定しがちです。大規模またはミッションクリティカルなネットワークでは必要な場合がありますが、高コストで複雑にもなります。ローカルサバイバビリティは、各拠点に中央基盤全体を複製せず、最も重要な拠点内通信機能を守る集中的な方法です。
これは分散組織に適しています。支店はすべての高度機能を持つ完全な通信サーバーを必要としない場合があります。駅や工場も、完全なプラットフォーム複製を必要としないことがあります。必要なのは、切断時に基本通話、緊急ルーティング、ローカルサービスアクセスを維持することです。サバイバビリティはその実務要件に焦点を当てます。
構成はリスクに応じて拡張できます。低リスク支店ではローカル緊急通話と内線フォールバックだけで足りる場合があります。重要な産業施設では、ローカル登録、ローカルトランク、緊急電話、ページングアクセス、オペレーターコンソールのフォールバックが必要になる場合があります。交通ネットワークでは駅単位の継続性と、リンク復帰時の中央指令への制御された再接続が必要です。
拠点の重要度に合わせてサバイバビリティの深さを調整すれば、不要に重いインフラを全拠点へ配置せずにレジリエンスを高められます。目的は全拠点を完全に独立させることではなく、異常なネットワーク条件下で本当に必要な通信機能を残すことです。
サービス中断後の復旧時間を短縮する
ローカルサバイバビリティは、障害中にサービスが完全に崩壊しないため、運用への影響を小さくできます。中央経路が復旧すると、システムはローカルフォールバックから集中運用へ戻ります。この遷移は、プラットフォーム設計とプロジェクト要件により、自動または制御された形で行われます。
サバイバビリティがなければ、WAN障害は多くの二次問題を引き起こします。ユーザーは失敗する通話を繰り返し、オペレーターは苦情を受け、緊急ルーティングは不確実になり、保守担当者は近くの端末同士が通信できない理由を説明しなければなりません。復旧とは回線を戻すだけでなく、ユーザーの信頼とサービス秩序を戻すことでもあります。
サバイバビリティがあれば、拠点は限定的でも整理されたモードで運用を続けます。一部の中央サービスが利用できないことにユーザーは気づくかもしれませんが、重要通信は可能です。主基盤が戻れば、登録、ルーティング、ポリシー制御を正常状態へ同期できます。障害は管理しやすくなり、日常業務への影響も小さくなります。
復旧計画には障害終了後の動作も含めるべきです。重複登録、ルーティング混乱、ユーザー状態の不一致、復帰遅延を避ける必要があります。保守チームは、拠点がいつサバイバブルモードに入ったか、どの通話がローカル処理されたか、いつ通常モードへ戻ったかを確認できるべきです。これらの記録はフェイルオーバーの正しさを確認します。
劣化状態でもユーザー体験を保つ
ユーザーは通常、呼サーバー、WANルーティング、SIP登録、トランクフォールバックを意識しません。必要な時に電話、緊急端末、インターコム、コンソールが動くことを期待します。ローカルサバイバビリティは、広域ネットワークに障害があっても、最も慣れた通信操作を利用できるようにして体験を保ちます。
たとえば、ユーザーはローカル内線を呼び、警備室へ連絡し、制御室へ到達し、緊急呼出点を起動できます。システムはフォールバックモードで動作していても、重要作業に必要な範囲では通常に近い体験を提供します。これにより混乱を減らし、非公式な代替手段へ流れることを防ぎます。
ユーザー体験を維持することは、教育負担の軽減にもつながります。フォールバック動作が普段のダイヤルパターンや応答経路に沿っていれば、ネットワーク障害用の別手順を覚える必要がありません。障害時にユーザーへ行動変更を強いるのではなく、システムが障害へ適応すべきです。
ただし、すべての機能をローカルに残せるわけではありません。集中ディレクトリ、遠隔録音、拠点間会議、クラウドボイスメール、グローバルルーティングなどの高度なサービスは、隔離中には使えない場合があります。良い導入では、ローカルで保証される機能と中央依存の機能を明確に区別します。
オペレーターが信頼できるフェイルオーバールールを設計する
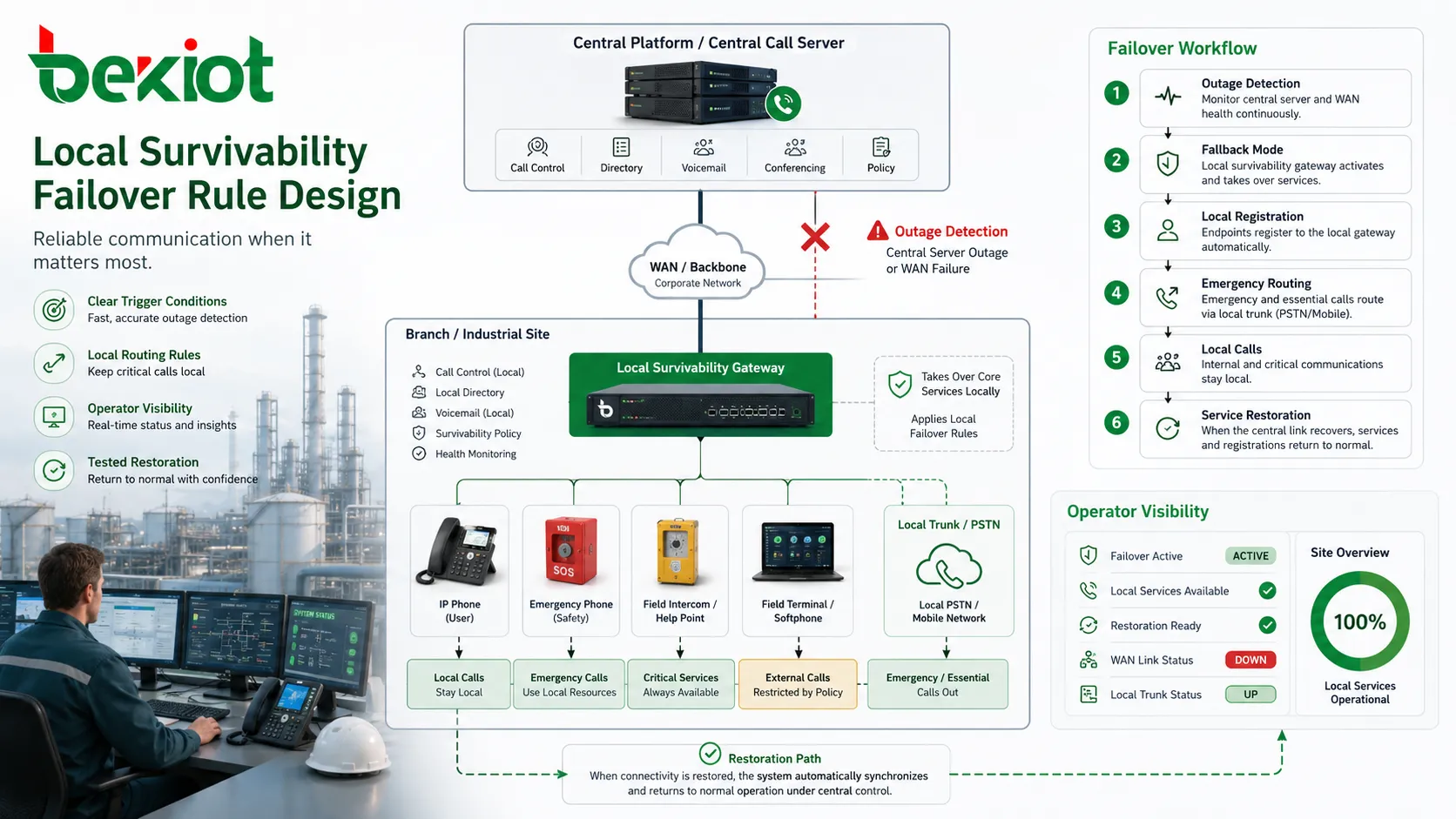
サバイバビリティはルールに依存します。システムは、いつフォールバックモードへ入るか、どのサービスをローカルで引き継ぐか、どの番号をローカル資源で処理するか、いつ通常運用へ戻るかを知っていなければなりません。ルールが曖昧だと、安定ではなく混乱を生みます。
トリガー条件は最初の設計課題です。中央呼サーバーとの接続喪失、SIP登録失敗、WAN遅延のしきい値超過、主トランクの利用不能などで、拠点はサバイバブルモードへ入ることがあります。不要な切替を避けるほど具体的であり、ユーザーが広範な障害を感じる前に応答できるほど敏感である必要があります。
ルーティングルールも重要です。適切なローカル通話はローカルに留めるべきです。緊急通話は現地オペレーターまたはバックアップトランクへ送れます。ローカルトランク容量が限られる場合、外線は重要番号に制限できます。他拠点への通話は遮断、再ルーティング、または代替経路で処理できます。オペレーターは障害前にこれらのルールを理解している必要があります。
信頼はテストと文書から生まれます。スタッフがサバイバブルモードの意味を知らなければ、正しく動作していてもシステム故障と誤解する可能性があります。明確な状態表示、保守ログ、操作ガイド、定期的なフェイルオーバーテストが信頼を作ります。誰も理解していない設計は、十分な運用価値を発揮しません。
支店および多拠点構成の導入計画
ローカルサバイバビリティは拠点の役割に合わせて計画すべきです。小規模支店、大規模工場、公共交通駅、キャンパス棟、遠隔ユーティリティ施設、緊急指令拠点は、同じ設計を必要としません。最初の手順は、中央プラットフォームへ到達できない時にも残すべき通信機能を特定することです。
重要な質問には、ローカル内線同士の通話が必要か、緊急通話を現地デスクへ送るか外部トランクへ送るか、公衆網アクセスが必要か、ローカルページングや放送が必要か、無線やインターコムリンクを維持するか、同時通話数はいくつ必要か、拠点はどれだけ隔離され得るか、などがあります。これらがローカルノードの規模と機能を決めます。
ネットワーク設計も見直す必要があります。WANが停止しても、ローカル端末はフォールバックノードへ到達できなければなりません。ローカルスイッチング、VLAN設計、IPアドレス、DHCP動作、DNS依存、バックアップ電源、ゲートウェイ配置が重要です。端末が同時にネットワークや電源を失えば、サバイバビリティ機能は働きません。
多拠点展開では設定の一貫性が重要です。各拠点に固有のローカルルールがあっても、全体設計は可能な限り標準パターンに従うべきです。標準テンプレートは設計ミスを減らし、保守を容易にします。高リスクまたは特殊用途の拠点には個別例外を追加できます。
運用監視と保守上の価値
ローカルサバイバビリティは一度設定して忘れる機能ではありません。その価値はローカルフォールバック経路が健全であり続けるかに左右されます。保守チームは、ローカルゲートウェイ、バックアップトランク、端末登録動作、電源状態、ソフトウェアバージョンを監視すべきです。オフラインまたは設定ミスのノードは、実際の障害まで気づかれない可能性があります。
定期テストは不可欠です。エンジニアは中央サーバー不可用やWAN断を制御された形で模擬し、ローカル通話、緊急通話、フォールバック経路が期待通り動作するか確認します。安全や運用継続が重要な環境では、これらのテストを記録する必要があります。
監視にはイベント記録も含めるべきです。拠点がサバイバブルモードへ入ると、システムはログやアラームを生成し、保守担当者が何が起きたかを理解できるようにします。フェイルオーバーが頻発する場合、WAN不安定、中央サーバー到達性、しきい値設定、ローカルネットワーク問題が原因かもしれません。サバイバビリティはサービスを守りますが、頻繁な発動は修正すべき根本問題を示します。
実際の障害後、記録は性能評価に役立ちます。ローカル通話は維持されたか、緊急通話は正しくルーティングされたか、ユーザーは混乱したか、システムは正常モードへきれいに戻ったか。これらの確認は設計改善と将来のレジリエンス向上につながります。
導入前に理解すべき一般的な制約
ローカルサバイバビリティは有用ですが、完全なシステム複製ではありません。隔離中は一部の中央サービスが利用できない場合があります。構成によっては、拠点間通話、集中録音、クラウドディレクトリ検索、高度な会議、集中ボイスメール、グローバルキュー、遠隔管理制御などが含まれます。これらの制約は導入前に説明しておくべきです。
容量にも制限があります。ローカルサバイバビリティノードは、定義された数のユーザー、通話、トランク、機能しか支えられない場合があります。WAN障害時に全ユーザーが通常通り利用することを期待するなら、フォールバックシステムもその規模に合わせる必要があります。緊急および重要通信だけが必要なら、より小さい設計で足りることもあります。
もう一つの制約はデータ一貫性です。フォールバック中、一部の通話記録、端末状態、設定変更はローカルに保存され、後で同期される場合があります。または中央プラットフォームへ完全には提供されない場合があります。プロジェクトでは、記録処理方法と監査・報告に必要な情報を定義する必要があります。
これらの制約を理解することは、サバイバビリティの価値を弱めません。むしろ導入を現実的にします。最も強い設計は、何がローカルで存続し、何が中央システムに依存し、劣化運用中にユーザーとオペレーターがどう行動すべきかを明確にします。
拠点単位レジリエンスの長期的な事業価値
ローカルサバイバビリティの長期価値は、分散環境での運用リスクを下げることにあります。単一の障害はまれでも、発生時のコストは高くなり得ます。通信喪失は保守遅延、生産停止、顧客対応低下、緊急対応の弱体化、安全リスクにつながります。サバイバビリティは、ネットワーク障害が全面的な運用障害へ発展する可能性を下げます。
多数の拠点を持つ組織では価値がさらに大きくなります。各拠点の接続問題が時々しか起きなくても、ネットワーク全体のリスクは大きくなります。ローカルフォールバック能力は、地理的に分散した拠点やリースWANリンクに依存する環境で、より強い運用モデルを作ります。
サバイバビリティは近代化も支えます。組織は集中型またはクラウド型通信基盤へ移行しながら、重要拠点にはローカル保護を残せます。新しい構成がすべてのローカル独立性を消すわけではないため、移行リスクが下がります。集中効率と拠点レベルの継続性を組み合わせることができます。
実際の導入において、ローカルサバイバビリティは単なる技術機能ではありません。事業継続の手段であり、安全を支える層であり、分散通信アーキテクチャを現実のネットワーク問題に強くする方法です。
よくある質問
ローカルサバイバビリティは大規模組織だけに必要ですか?
いいえ。WANまたは中央サーバー障害時にも通信を継続する必要がある拠点なら有用です。小規模支店、遠隔施設、産業ステーション、キャンパス、交通拠点も、通信喪失の影響が大きい場合はローカルフォールバックが必要です。
ローカルサバイバビリティは中央冗長を置き換えますか?
いいえ。中央冗長は主プラットフォームを保護し、ローカルサバイバビリティは拠点が中央プラットフォームへ到達できない時の現場通信を保護します。両者はレジリエンスの異なる部分を解決し、併用できます。
サバイバブルモードで通常残るサービスは何ですか?
一般的には、ローカル内線通話、緊急ルーティング、ローカルトランクアクセス、限定的な登録フォールバック、事前定義された重要通信経路が残ります。高度な集中サービスは、ローカル運用向けに設計されていない限り利用できない場合があります。
サバイバビリティのフェイルオーバーはどのくらいの頻度でテストすべきですか?
頻度はリスクレベルによりますが、重要拠点では定期的に、また大きなネットワークや設定変更後にテストすべきです。ローカル通話、緊急経路、トランクアクセス、復旧動作、オペレーター可視性を確認します。
最も多い導入ミスは何ですか?
最も多いのは、完全なフォールバックワークフローを設計せずに機能だけを有効化することです。依存する前に、トリガー、ローカルルーティング、緊急動作、容量、ユーザー期待、監視、復旧手順を定義する必要があります。







