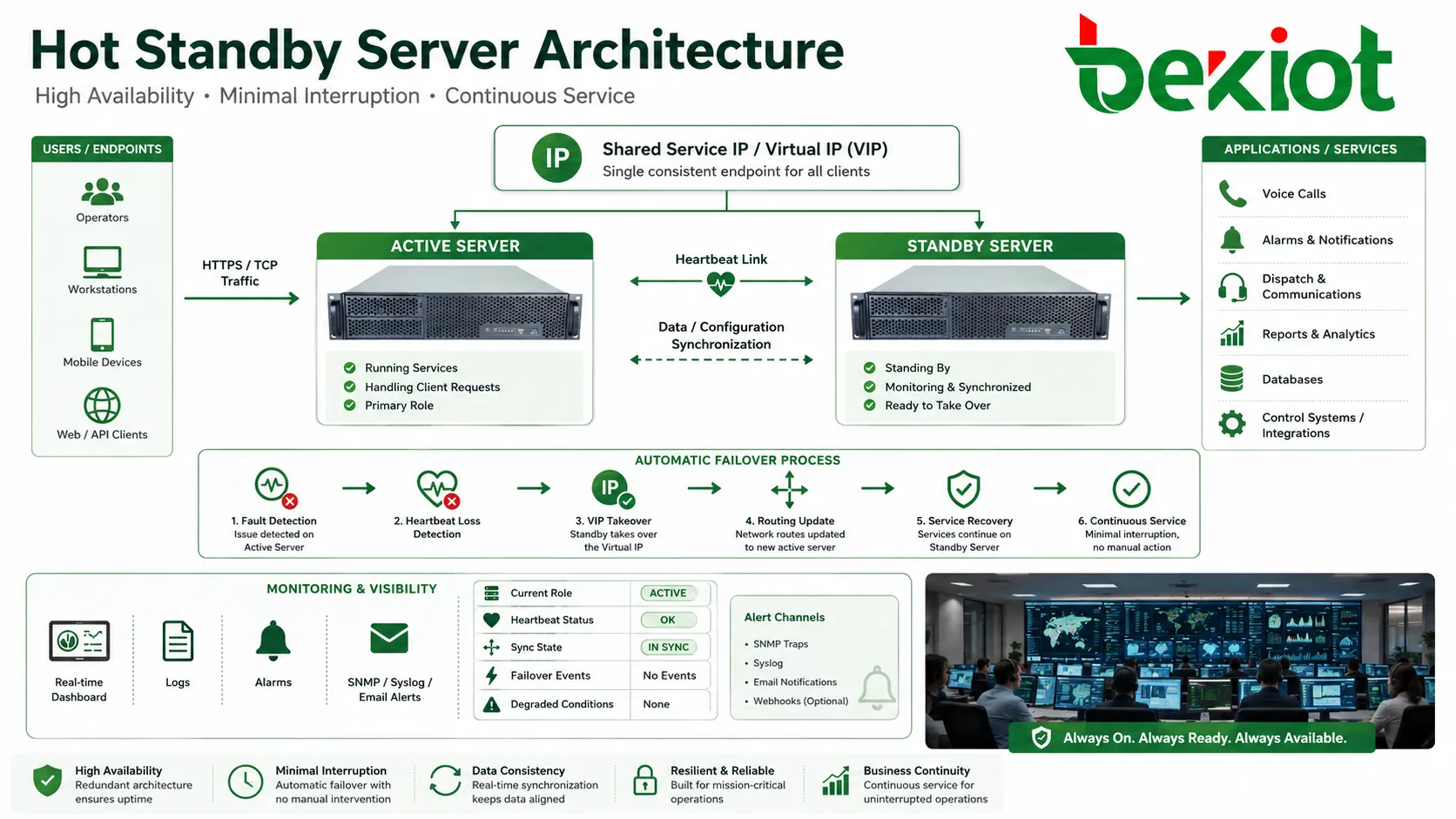
ホットスタンバイは、予備装置、サーバー、コントローラー、ゲートウェイ、またはプラットフォームを通電・同期・監視された状態に保ち、稼働側が故障したときに引き継げるようにする高可用設計です。手動修理やコールドスタートを待つのではなく、自動フェイルオーバーによって待機側がサービスを担い、停止時間を減らして重要システムの継続性を守ります。
この機能は、通信プラットフォーム、データセンター、産業制御、セキュリティ、電力インフラ、交通ネットワーク、クラウドサービス、通信ゲートウェイ、緊急システム、企業アプリケーションで使われます。価値は単なる予備機ではなく、待機ユニットが接続、監視、同期、試験され、本番ノードが使えないときに実際に稼働できる点にあります。
予備装置からサービス継続設計へ
従来のバックアップは障害が起きるまで使われないことがあります。ホットスタンバイは違い、予備要素がすでに稼働中の構成に組み込まれています。ハートビートを監視し、設定更新を受け取り、サービス状態を追跡し、最小限の中断で引き継ぐ準備をします。
利用者から見る理想は単純です。通話が続き、セッションが復旧し、アラームが見え続け、制御システムが利用でき、オペレーターが手作業でサービスを再構築しなくてよい状態です。その裏では、データ同期、IP引き継ぎ、サービス状態、ルーティング更新、障害検出、復旧順序を設計する必要があります。
企業や産業の現場では、最大性能より高可用性が重要になることが多くあります。少し遅くても継続して利用できるシステムは、保護なしで停止する高性能システムより価値が高い場合があります。
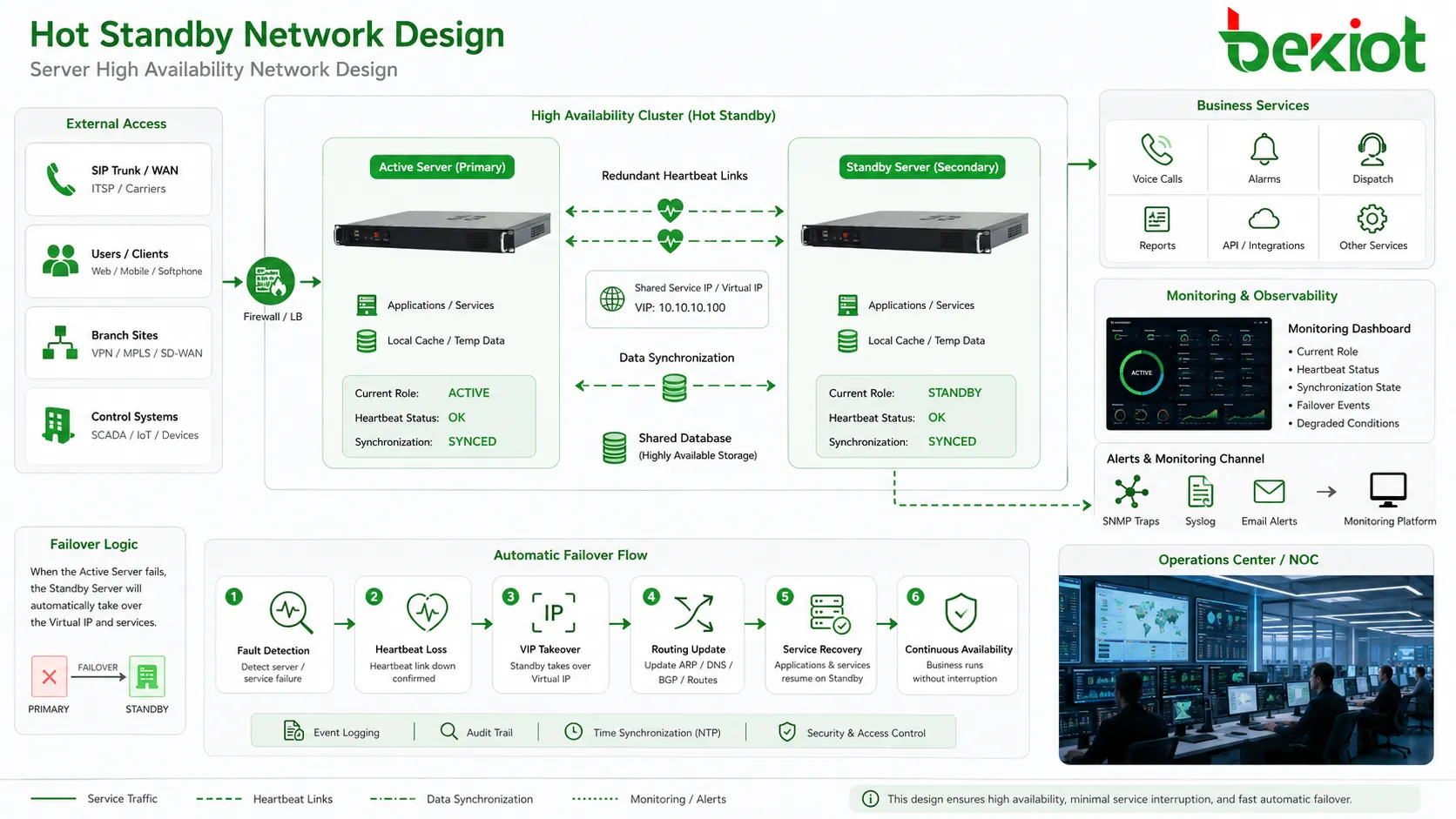
接管プロセスの仕組み
ハートビート検出
アクティブノードとスタンバイノードは通常、ハートビート信号を交換します。この信号は双方が動作しており、主ノードがまだサービスを担当していることを確認します。ハートビートは専用ケーブル、管理ネットワーク、プライベートVLAN、冗長ネットワーク経路を通る場合があります。
スタンバイノードが定められた時間内に有効なハートビートを受信しなくなると、アクティブノードの障害を疑います。その後、フェイルオーバー判断が始まります。一時的なネットワーク遅延に過敏に反応すると誤切替が起きるため、このロジックは慎重に設計する必要があります。
状態同期
滑らかな移行には、スタンバイ側が最新情報を持っている必要があります。設定ファイル、ユーザーデータ、ルーティングテーブル、セッション記録、通話状態、アラーム状態、データベース項目、ライセンス、端末登録情報、制御ロジックなどが含まれます。
設定だけを同期するシステムもあれば、リアルタイムのサービス状態まで同期するシステムもあります。同期が深いほど切替は滑らかになりますが、リアルタイム同期は複雑さとネットワーク依存も高めます。
障害判定
障害の可能性を検出した後、システムはアクティブノードが本当に利用不能か判断します。ハートビート喪失、プロセス状態、ディスク、インターフェース、データベース応答、CPU負荷、電源アラーム、外部監視入力などを確認します。
良い設計では、一つの条件だけで判断しません。例えば、一つのハートビートリンクを失っても、別の管理経路でアクティブノードが正常と確認できるなら、自動的に接管すべきではありません。
役割切替
フェイルオーバーが確定すると、スタンバイノードは役割を変えてアクティブになります。仮想IPを取得し、サービスを起動し、ルートを広告し、相手機器へ登録し、トランクを有効化し、データベースのマスター役割を取り、通話やアラームを処理します。
元のアクティブノードは隔離、再起動、修理、または後でスタンバイとして復帰させることができます。再参加の動作は、サービス競合を避けるために管理される必要があります。
主要なアーキテクチャモデル
アクティブ・スタンバイ構成
最も一般的な構成は、1台のアクティブノードと1台のスタンバイノードです。アクティブ側が本番サービスを処理し、スタンバイ側が待機しながら同期します。アクティブ側が故障すると、スタンバイ側が引き継ぎます。
このモデルは理解しやすく、PBX、ファイアウォール、ルーター、コントローラー、データベース、ストレージ機器、産業プラットフォームで広く使われます。ただし通常時はスタンバイ資源が十分に使われないことがあります。
スタンバイ論理を持つデュアルアクティブ
一部の環境では、両方のノードを稼働させながら相互のフェイルオーバーを用意します。通常時は各ノードが負荷の一部を処理し、一方が故障したときにもう一方がより多くのトラフィックを受け持ちます。
この設計は資源利用率を高めますが、負荷分散、同期、セッション処理、容量計画をより慎重に行う必要があります。通常時に各ノードが限界近くで動く場合、障害時の予備容量が不足します。
クラスタ型冗長化
大規模システムでは、単純な2ノード構成ではなくクラスタを使う場合があります。複数ノードがサービスを共有し、相互に監視し、一つのメンバーが故障したときに負荷を再配分します。
クラスタ構成は拡張性と耐障害性に優れますが、導入と保守はより複雑です。強い協調、クォーラム制御、ヘルスチェック、一貫した設定管理が必要です。
地理的に分離した保護
一部の重要システムでは、スタンバイ資源を別の建物、キャンパス、データセンター、地域に配置します。これにより、局所的な停電、火災、浸水、機器室障害、サイト全体の停止から保護できます。
地理的保護は災害復旧力を高めますが、遅延、データ整合性、ネットワークルーティング、運用調整の課題を生みます。すべてのサービスが長距離で滑らかに切り替えられるわけではありません。
| モデル | 適した用途 | 主な設計上の注意点 |
|---|---|---|
| アクティブ・スタンバイ | サーバー、ゲートウェイ、PBX、コントローラー向けの単純な高可用ペア。 | スタンバイ資源の利用率とフェイルオーバータイミング。 |
| デュアルアクティブ | 負荷分散と冗長化を同時に必要とするシステム。 | 予備容量、セッション分散、フェイルバック制御。 |
| クラスタ | 複数サービスノードと拡張可能な負荷を持つ大規模プラットフォーム。 | クォーラム、同期、スプリットブレイン防止、運用複雑性。 |
| 遠隔サイト保護 | 災害復旧とサイトレベルの耐障害性。 | 遅延、データ整合性、ネットワークルーティング、復旧手順。 |
信頼性を左右するネットワーク要素
ハートビート経路
ハートビート経路は信頼性が高く、できれば冗長であるべきです。通常のサービス通信と同じ不安定なネットワークを使うと、輻輳やスイッチ障害時にスタンバイノードが状態を誤判断することがあります。
重要な導入では、二つのハートビート経路、別々の物理リンク、または異なるスイッチ経路を使うことがあります。これにより、一つのネットワーク障害が誤った接管を引き起こす可能性を下げます。
仮想サービスアドレス
多くのシステムは仮想IPアドレスまたはフローティングサービスアドレスを使います。利用者や相手機器は個別ノードの物理アドレスではなく、この安定したアドレスへ接続します。フェイルオーバー時にアドレスはスタンバイ側へ移ります。
この方法はクライアント設定を簡単にしますが、ネットワーク機器はARP、ルーティング、DNS、セッションテーブルを素早く更新する必要があります。更新が遅いと、スタンバイがすでに有効でも切替が遅く見えます。
共有または複製データ
共有ストレージに依存するシステムもあれば、ノード間でデータを複製するシステムもあります。共有ストレージは整合性を取りやすい一方、保護しなければ単一障害点になります。複製は独立性を高めますが、遅延、競合、不完全な書き込みを扱う必要があります。
適切な方式は、設定の継続性、トランザクション整合性、録音の完全性、セッション保持、または単純なサービス再起動のどれを重視するかで決まります。
ルーティングとトランクの動作
通信システムは、SIPトランク、無線ゲートウェイ、PSTNゲートウェイ、指令卓、外部API、監視プラットフォーム、遠隔端末と接続されます。これらの外部システムは、フェイルオーバー後にどこへトラフィックを送るかを知る必要があります。
スタンバイノードがアクティブになっても、トランク、ルート、相手登録が更新されなければ、利用者はまだ中断を感じます。試験ではローカル2ノードだけでなく、上流と下流のシステムも含める必要があります。
管理・監視レイヤー
高可用性は管理者から見える必要があります。ダッシュボード、ログ、アラーム、SNMPトラップ、syslog、メール通知、監視平台は、現在の役割、ハートビート、同期状態、フェイルオーバーイベント、劣化状態を表示すべきです。
監視がなければ、システムは数週間スタンバイ側で静かに動き続けることがあります。その後さらに障害が起きると、残る保護がない可能性があります。
重要な技術機能
自動フェイルオーバー
自動フェイルオーバーは、手動介入なしにスタンバイ側をアクティブにします。リアルタイム通信、安全アラーム、制御操作、顧客向けサービスを支える場合には重要です。
フェイルオーバーの閾値は慎重に調整する必要があります。敏感すぎると誤切替が発生し、遅すぎると不要な停止時間が利用者に発生します。
手動切替
手動切替は、保守、アップグレード、試験、計画修理の際にサービスを一方のノードから他方へ移す機能です。ハードウェア交換、パッチ適用、スタンバイ準備状況の確認に有用です。
計画された切替は、予期しない故障を待つより安全です。チームが時間を決め、結果を監視し、必要ならロールバックできるからです。
フェイルバック制御
元のアクティブノードが修理された後、サービスを自動で戻すか、計画窓まで現在のアクティブに残すかを決める必要があります。自動フェイルバックは元の構成を早く戻せますが、新たな中断を生む場合があります。
多くの重要システムでは、再度サービスを移す前に健全性、同期、トラフィックを確認できるよう、手動フェイルバックを好みます。
スプリットブレイン防止
スプリットブレインは、二つのノードが同時に自分をアクティブと判断する状態です。重複サービス、データベース競合、通話ルーティング誤り、IP競合、データ破損につながります。
防止策には、クォーラム、ウィットネスノード、フェンシング、優先度ルール、冗長ハートビート、厳格な役割制御があります。スプリットブレイン防止は高可用設計の最重要部分の一つです。
データ整合性保護
フェイルオーバー中、システムは設定データと運用データを保護しなければなりません。データベース取引、通話記録、アラームログ、端末登録状態、録音、イベント履歴が対象です。
データ完全性は、コンプライアンス、課金、緊急記録、指令ログ、監査証跡を扱うシステムで特に重要です。
この設計が使われる場所
企業通信プラットフォーム
PBXサーバー、SIPプラットフォーム、ボイスメール、録音サーバー、コンタクトセンター、統合通信プラットフォームは、業務通話を維持するためにスタンバイ保護を利用できます。アクティブサーバーが故障しても、予備側が登録、通話、ルーティング、サービスロジックを処理できます。
重要通信プロジェクトでは、Becke Telcom は通信システム計画に高可用の考え方を取り入れ、サーバー冗長化、ゲートウェイ継続性、指令可用性、フェイルオーバー経路を全体設計の一部として検討します。
産業制御と SCADA
産業システムでは、スタンバイコントローラー、冗長SCADAサーバー、二重通信ゲートウェイ、予備操作ステーションが使われます。これらは生産、安全、エネルギー、ユーティリティ、プロセス監視を支えます。
フェイルオーバーは実際のプロセス条件で試験すべきです。実験室で正しく役割切替できる制御システムも、現場機器、PLC、ヒストリアン、アラーム、操作卓に接続されると異なる動作を示すことがあります。
セキュリティと監視システム
映像管理サーバー、入退室管理、アラームサーバー、ストレージノード、制御室システムは、監視の空白やセキュリティ対応遅延を避けるためにスタンバイ保護を必要とする場合があります。
これらの環境では、ライブ映像、録画継続、ドア制御、アラーム確認、イベントログ、オペレーター権限をフェイルオーバー設計に含める必要があります。
データセンターとクラウドサービス
サーバー、データベース、ファイアウォール、ロードバランサー、ストレージ、ルーター、アプリケーションは高可用構成を使うことが多くあります。スタンバイ保護はハードウェア、仮想化、コンテナ、データベース、アプリケーション層に存在します。
関与する層が増えるほど、どの層がフェイルオーバーを担当するかを明確にすることが重要です。複数の独立した切替機構は、計画が不十分だと競合します。

公共安全と交通
緊急対応センター、鉄道、トンネル制御室、空港運用、港湾指令、交通管理は高いサービス可用性を必要とします。通信障害は対応を遅らせ、状況認識を下げ、連携を中断します。
これらのシステムでは、サーバーだけでなく、電源、ネットワークスイッチ、トランク、端末、操作席、外部インターフェースまで冗長化する必要があります。
停止時間削減を超える導入効果
最も明確な利点はサービス継続性です。主ノードが故障しても、利用者は少ない中断で作業を続けられます。これは音声通信、アラーム、監視、データアクセス、制御機能に重要です。
もう一つの利点は計画保守の柔軟性です。管理者はサービスをスタンバイ側へ移し、元のノードを保守し、確認後に通常役割へ戻せるため、長い停止時間を減らせます。
スタンバイ設計はシステム更新への安心感も高めます。一方の更新で問題が出ても、アーキテクチャとロールバック計画が正しく設計されていれば、サービスを制御された形で回復できます。
管理チームにとって、高可用性はリスク管理を支援します。単一装置の故障を全面停止ではなく、調査と修理が可能な管理イベントに変え、業務影響を減らします。
実際の障害シナリオ
ハードウェア障害
サーバー、電源、ディスク、インターフェースカード、ゲートウェイ、コントローラーは故障する可能性があります。スタンバイノードはアクティブサービスが健全でないことを検出し、設定された方針に従って引き継ぐ必要があります。
ハードウェア障害は理解しやすいシナリオですが、サービス中断の最も多い原因とは限りません。
アプリケーションプロセスの停止
機械自体は通電していても、サービスアプリケーションが応答しなくなる場合があります。良いヘルスチェックは、サーバーが生きているかだけでなく、サービス自体が動作しているかを確認します。
ping応答だけを確認するのは通常不十分です。システムがpingに応答しても、通話エンジン、データベース、アラーム処理、Webサービスが停止している場合があります。
ネットワーク分離
ノードが利用者から隔離されていても、自分は健全だと判断する場合があります。これは、どちらがアクティブであるべきかをシステムが判断できなくなるため危険です。
冗長ネットワーク経路とクォーラムロジックは、分離イベントで誤った判断を避ける助けになります。
データベース破損
アクティブ側でデータが破損し、その破損がすぐスタンバイ側へ複製されると、冗長化だけでは問題を解決できません。バックアップとバージョン付き復旧が必要です。
高可用性はバックアップと同じではありません。スタンバイノードはサービス継続性を守り、バックアップは過去データの復旧を守ります。
オペレーターの誤操作
誤った設定、誤削除、間違ったルーティング、失敗したアップグレードは、設定が自動同期されている場合、両方のノードに影響します。
変更管理、承認フロー、設定エクスポート、ロールバック計画は、人為的ミスの影響を減らすために不可欠です。
高可用性は部品故障による停止を減らしますが、バックアップ、サイバーセキュリティ、変更管理、監視、規律ある保守の代わりにはなりません。
試験と受入の戦略
フェイルオーバーは本番引き渡し前に試験すべきです。試験では、スタンバイ側が障害を検出し、サービスを引き継ぎ、ネットワーク経路を更新し、外部接続を復旧し、必要データを保持し、適切なアラームを出すことを確認します。
試験には、計画切替、アクティブノード停止、サービスプロセス障害、ネットワークリンク障害、安全な範囲での電源障害、修理後の復旧を含めます。各試験では期待動作と許容中断時間を定義します。
受入記録には、フェイルオーバー時間、データ整合性結果、サービス可用性、アラーム記録、ログ証拠、操作員確認、未解決事項を含めます。記録がなければ、冗長に見えても実証されていない状態です。
運用と保守の指針
スタンバイ状態は継続監視が必要です。通電していても同期が外れたスタンバイノードは準備完了ではありません。管理者はハートビート、複製遅延、資源使用、サービス状態、ライセンス、ストレージ、ソフトウェア版の一致を確認します。
両側は慎重に更新します。バージョン不一致はフェイルオーバー失敗や予期しない動作につながります。更新は段階的に行い、欠陥更新が両ノードを同時に壊さないよう試験します。
定期的な切替訓練を行います。管理された条件で試験されていないシステムは、実際の障害時に動かない可能性があります。訓練は操作員が手順と応答時間を理解する助けにもなります。
各フェイルオーバー後にログを確認します。サービスが正常に見えても原因を調べるべきです。繰り返し発生する場合、ネットワーク不安定、資源過負荷、機器劣化、ヘルスチェック閾値の問題を示すことがあります。
FAQ
ホットスタンバイはバックアップと同じですか?
いいえ。スタンバイノードはサービス継続のために使われ、バックアップはデータ復旧のために使われます。フェイルオーバーは破損または削除された古いデータを戻せないため、通常は両方が必要です。
フェイルオーバーはどのくらい速く行うべきですか?
許容時間は用途によって異なります。音声、制御、アラーム、公共安全システムは、通常のレポートやアーカイブシステムより速い復旧を必要とします。
スタンバイシステムはソフトウェアバグを防げますか?
場合によります。同じバグが両ノードに存在する場合、フェイルオーバーでは解決できません。バージョン管理、試験、ロールバック、バックアップは依然として重要です。
スプリットブレインの原因は何ですか?
スプリットブレインは、ハートビート喪失、ネットワーク分離、弱いクォーラム設計、誤ったフェイルオーバールールで発生することが多いです。複数のノードが自分をアクティブと考える状態です。
フェイルオーバー後に何を確認すべきですか?
フェイルオーバー後は、アクティブ役割、スタンバイ健全性、同期状態、サービスログ、利用者影響、データ完全性、外部トランクやインターフェース、アラーム記録、根本原因を確認します。