HTTP、つまり Hypertext Transfer Protocol は、クライアントとサーバーの間で Web ページ、API データ、ファイル、フォーム、画像、スクリプト、その他のリソースを転送するために使われるアプリケーション層のプロトコルです。これは World Wide Web の基盤であり、現代のインターネットシステムで最も広く使われている通信プロトコルの一つです。
ユーザーが Web サイトを開く、リンクをクリックする、フォームを送信する、画像を読み込む、または API を呼び出すとき、HTTP はクライアントがどのようにリソースを要求し、サーバーがどのように応答するかを定義します。プロトコル自体は、ページの見た目やアプリケーションの動作を決めるものではありません。主な役割は、二者間に構造化された通信方法を提供することです。
リクエストとレスポンスの対話
基本的な動作原理は単純です。クライアントがリクエストを送り、サーバーがレスポンスを返します。クライアントは通常、Web ブラウザ、モバイルアプリ、デスクトップアプリケーション、API ツール、クローラー、または組み込みデバイスです。サーバーは、要求されたリソースやサービスをホストするシステムです。
たとえば、ブラウザが Web サイトにアクセスすると、特定のページを求めるリクエストを送信します。サーバーはそのリクエストを受け取り、どのリソースが要求されているかを確認し、背後のルールを処理して、コンテンツ、状態情報、メタデータを含むレスポンスを返します。
このモデルはリクエスト-レスポンス通信と呼ばれます。クライアントが交換を開始し、サーバーが応答します。各交換は構造化されているため、双方は何が要求され、どのように処理され、どの結果が返されたのかを理解できます。

最初のバイトが動く前に
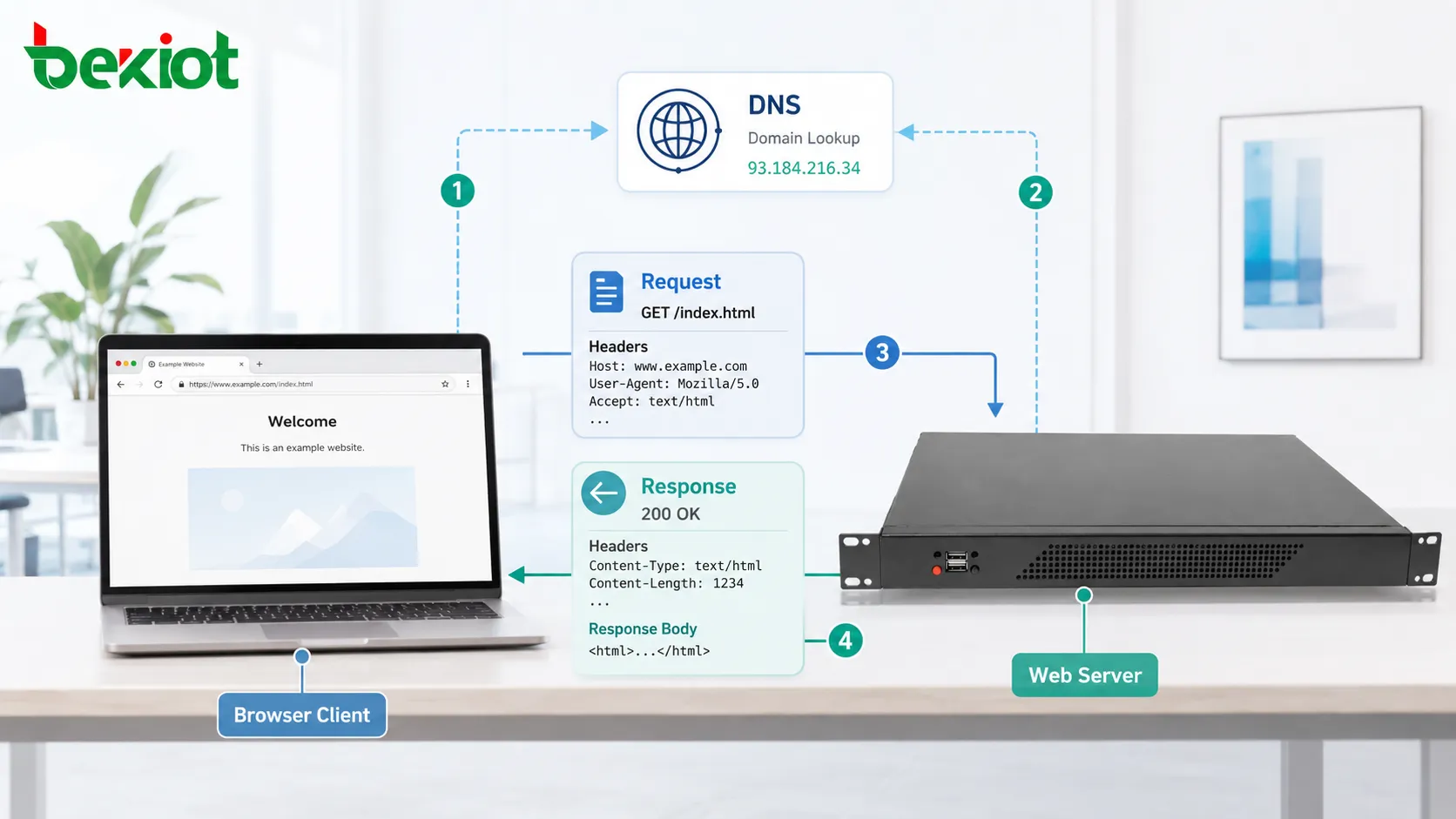
HTTP リクエストがサーバーに到達する前に、クライアントは送信先を知る必要があります。ユーザーがドメイン名を入力すると、ブラウザは通常、まず DNS 解決を行います。DNS は、人間が読めるドメイン名を IP アドレスに変換します。
その後、クライアントはサーバーへのネットワーク接続を確立します。従来の TCP 上の HTTP では、これは TCP 接続を開くことを意味します。HTTPS では、通信を暗号化し認証できるように TLS ハンドシェイクも実行されます。
これらの手順の後で初めて、実際の HTTP メッセージを交換できます。つまり、Web ページの読み込みはプロトコルメッセージだけの問題ではありません。DNS、トランスポート接続、暗号化、サーバーの可用性、ルーティング、ネットワーク性能にも依存します。
クライアントリクエストの構造
HTTP リクエストには通常、メソッド、対象パス、バージョン、ヘッダー、そして場合によってメッセージ本文が含まれます。メソッドは意図された操作を示します。パスはリソースを識別します。ヘッダーは追加情報を提供します。本文は必要に応じて送信データを運びます。
単純なリクエストはホームページを要求するだけかもしれません。より複雑なリクエストでは、ログイン情報を送信したり、ファイルをアップロードしたり、JSON データを API に送ったり、キャッシュ済みリソースが変更された場合だけ要求したりします。
一般的なリクエストメソッドには GET、POST、PUT、PATCH、DELETE、HEAD、OPTIONS があります。各メソッドには異なる意味があり、操作の目的に応じて使う必要があります。
GET は通常、データの取得に使われます。POST はデータの送信によく使われます。PUT と PATCH はリソースの更新に使われます。DELETE は削除の要求に使われます。HEAD は完全な本文なしでレスポンスヘッダーだけを要求します。OPTIONS はサポートされる通信オプションを確認します。
サーバーがメッセージを解釈する方法
リクエストを受け取ると、サーバーはメソッド、パス、ヘッダー、本文、Cookie、認証データ、ルーティングルールを読み取ります。その後、何を行うべきかを判断します。
リクエストが静的ファイルに対するものであれば、サーバーはそのファイルを直接返せます。動的ページや API エンドポイントに対するものであれば、アプリケーションコードの呼び出し、データベース照会、ユーザー権限の確認、業務ロジックの実行、または他サービスとの通信を行うことがあります。
サーバーは何かを返す前にセキュリティルールを適用することもあります。リクエストが認証済みか、ユーザーに権限があるか、リクエスト形式が不正でないか、送信元がブロックされていないか、またはレート制限を超えていないかを確認できます。
最終結果は HTTP レスポンスとしてパッケージ化されます。
レスポンスの構造と意味
HTTP レスポンスには通常、ステータスコード、ヘッダー、任意の本文が含まれます。ステータスコードは、リクエストが成功したのか、失敗したのか、リダイレクトされたのか、または追加操作が必要なのかをクライアントに伝えます。
ヘッダーはレスポンスを説明します。コンテンツタイプ、コンテンツ長、キャッシュ規則、Cookie、サーバー情報、圧縮方式、セキュリティポリシー、リダイレクト先などを含むことがあります。
本文は実際に返される内容を運びます。HTML、JSON、XML、画像データ、動画セグメント、テキストファイル、スタイルシート、スクリプト、またはバイナリダウンロードである場合があります。
ブラウザはレスポンス本文とヘッダーを使って、何を表示するか、何をキャッシュするか、何を実行するか、何をダウンロードするか、追加リクエストが必要かを判断します。
交通信号のようなステータスコード
ステータスコードは、クライアントが結果をすばやく理解するのに役立ちます。これらはカテゴリ別に分類されています。
| コード範囲 | 一般的な意味 | 使用例 |
|---|---|---|
| 100-199 | 情報レスポンス | 処理の継続またはプロトコルレベルの通知 |
| 200-299 | 成功レスポンス | ページ読み込み完了、API がデータを返却、ファイル配信完了 |
| 300-399 | リダイレクト | リソースが移動した、またはクライアントが別の URL を要求すべき状態 |
| 400-499 | クライアント側エラー | 不正なリクエスト、認証されていないアクセス、リソースが見つからない |
| 500-599 | サーバー側エラー | アプリケーション障害、ゲートウェイエラー、サーバー過負荷 |
200 レスポンスは通常、リクエストが成功したことを意味します。301 または 302 レスポンスは、クライアントが別の場所へ移動すべきことを示します。404 レスポンスは要求されたリソースが見つからないことを意味します。500 レスポンスはサーバー内部で問題が発生したことを意味します。
ステータスコードはブラウザだけのものではありません。API クライアント、監視システム、クローラー、プロキシ、ロードバランサーも判断に利用します。
ヘッダーはコンテキストを運ぶ
ヘッダーは交換のコンテキストを提供するキーと値のフィールドです。データ形式、言語の優先、圧縮、認証、キャッシュ動作、Cookie、接続動作、セキュリティ要件を双方が記述するのに役立ちます。
たとえば、Accept ヘッダーはクライアントが好むコンテンツタイプをサーバーに伝えます。Content-Type ヘッダーは本文が使う形式を受信側に伝えます。Authorization ヘッダーは資格情報やトークンを運ぶ場合があります。Cache-Control ヘッダーはキャッシュ動作を定義します。
ヘッダーによってプロトコルは柔軟になります。同じリクエスト-レスポンスモデルで、Web サイト、API、ファイルダウンロード、ストリーミングセグメント、認証フロー、サービス連携を支えられます。ヘッダーが基本メッセージ構造を変えずに追加指示を提供するためです。
ステートレス設計とセッション処理
HTTP はしばしばステートレスと説明されます。これは、各リクエストがデフォルトで独立していることを意味します。サーバーは基本的なプロトコルモデルの一部として、過去のリクエストを自動的に記憶しません。
しかし、実際の多くの Web サイトやアプリケーションにはセッション動作が必要です。ユーザーはログインし、商品をカートに追加し、設定を変更し、多くのリクエストをまたいで作業を続けます。これを支えるために、システムは Cookie、セッション ID、トークン、ローカルストレージ、サーバー側セッション、認証ヘッダーを使います。
プロトコルはリクエストベースのままですが、アプリケーションはその上に継続性を構築します。そのため、基盤となる交換が個別のリクエストとレスポンスで構成されていても、Web サイトはユーザーを記憶できます。
URL によるリソース識別
URL は、リソースがどこにあり、どのように要求すればよいかをクライアントに伝えます。通常、スキーム、ホスト、パス、クエリ文字列、そして場合によってポートやフラグメントを含みます。
スキームは http または https です。ホストはドメインを識別します。パスは特定のリソースやルートを指します。クエリ文字列は追加パラメータを運びます。フラグメントは通常クライアント側で処理され、メインのリクエストパスと同じ形でサーバーに送る必要はありません。
URL は Web リソースをアドレス指定可能にします。ブラウザ、API、検索エンジン、アプリケーション、ユーザーが一貫した形式でリソースを参照できるようにします。
Web ページが読み込まれるときに起こること
1 回のページ読み込みには、多くの HTTP 交換が含まれることがあります。最初のリクエストはメインの HTML 文書を取得します。その文書を読んだ後、ブラウザは CSS ファイル、JavaScript ファイル、画像、フォント、アイコン、分析スクリプト、API 呼び出し、メディアファイルなどの追加リソースを見つけます。
各リソースには別のリクエストが必要になる場合があります。一部のリソースは同じサーバーから来ますが、他のリソースは CDN、サードパーティサービス、広告システム、地図プロバイダー、API ゲートウェイから来ることもあります。
その後ブラウザは受信したリソースを組み合わせ、ページ構造を構築し、スタイルを適用し、スクリプトを実行して、最終的な視覚インターフェースを描画します。これが、1 つの見える操作の背後で数十回、場合によっては数百回のプロトコル交換が必要になる理由です。
キャッシュと性能向上
キャッシュにより、クライアント、ブラウザ、プロキシ、CDN、サーバーは、適切な場合に以前ダウンロードしたリソースを再利用できます。これにより、繰り返しのデータ転送が減り、遅延が低下し、帯域幅が節約され、ユーザー体験が向上します。
キャッシュ動作は Cache-Control、ETag、Last-Modified、Expires などのヘッダーで制御されます。これらのヘッダーは、リソースを再利用できるか、再検証が必要か、再度ダウンロードすべきかを判断するのに役立ちます。
画像、スクリプト、スタイルシートなどの静的ファイルでは、キャッシュによって読み込み時間を大きく短縮できます。動的データでは、古い内容が誤った結果を生む可能性があるため、キャッシュは慎重に使う必要があります。
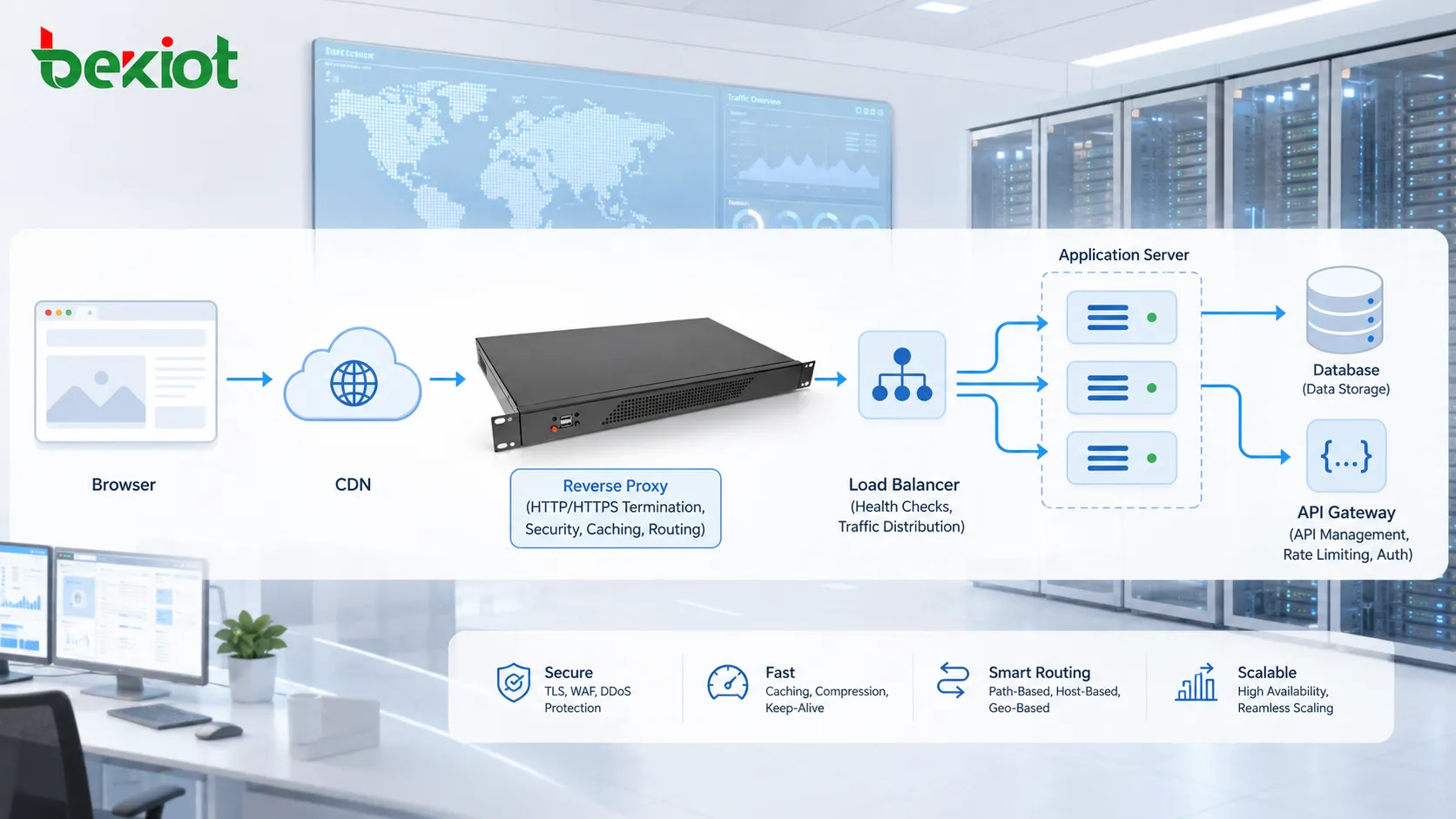
プロキシ、ゲートウェイ、CDN の役割
HTTP トラフィックは、必ずしもブラウザからオリジンサーバーへ直接移動するわけではありません。リバースプロキシ、フォワードプロキシ、API ゲートウェイ、ロードバランサー、ファイアウォール、CDN エッジノード、セキュリティ検査システムを通過することがあります。
リバースプロキシはバックエンドサーバーに代わってリクエストを受け取ることがあります。ロードバランサーは複数のアプリケーションサーバーにトラフィックを分配します。CDN はユーザーに近い場所にコンテンツをキャッシュします。API ゲートウェイはトークン検証、リクエストレート制限、ヘッダー変換、マイクロサービスへのルーティングを行うことがあります。
これらの中間システムは、拡張性、セキュリティ、性能、管理性を向上させます。同時に、異なる層でエラーが発生する可能性があるため、トラブルシューティングはより複雑になります。
HTTPS と安全な通信
HTTPS は TLS 暗号化の上で運ばれる HTTP です。クライアントとサーバー間の通信を暗号化することで、転送中のデータを保護します。また、デジタル証明書によってサーバーの身元確認を助けます。
暗号化がなければ、パスワード、トークン、個人データ、セッション Cookie などの機密情報がネットワーク上の攻撃者にさらされる可能性があります。HTTPS はこのリスクを減らし、現代の Web サイトと API の標準になっています。
安全な通信は、正しい証明書設定、強力なプロトコルバージョン、安全な Cookie、適切なリダイレクト、安全なサーバー設定にも依存します。HTTPS は不可欠ですが、正しく設定されなければなりません。
プロトコルバージョンの進化
HTTP は性能と効率を高めるために進化してきました。初期バージョンはより単純なリクエスト処理を使用していました。後のバージョンでは、持続的接続、多重化、ヘッダー圧縮、サーバープッシュの概念、改善されたトランスポート動作が導入されました。
HTTP/1.1 は接続再利用を改善し、広く導入されました。HTTP/2 は多重化を導入し、複数のリクエストとレスポンスが 1 つの接続をより効率的に共有できるようにしました。HTTP/3 は UDP 上の QUIC を使用し、接続確立を改善し、特定のネットワーク条件で一部の遅延問題を減らします。
動作原理はリクエスト-レスポンス通信のままですが、トランスポートと性能の仕組みはより高度になっています。
API と機械間通信
HTTP はブラウザだけで使われるものではありません。多くの API における主要なプロトコル形式でもあります。モバイルアプリ、Web アプリケーション、IoT プラットフォーム、クラウドサービス、決済システム、監視ツール、企業システムは、HTTP 上で JSON や XML データを交換することがよくあります。
API 通信では、レスポンス本文が HTML ページでない場合があります。別のプログラムが処理する構造化データであることがあります。ステータスコード、ヘッダー、認証トークン、リクエストメソッドは、予測可能な連携のために特に重要です。
そのため、開発者は基本的な動作モデルと、API 設計で使われる実践的な慣習の両方を理解する必要があります。
よくある問題と原因
ページが遅い原因には、DNS 遅延、大きなファイル、不適切なキャッシュ、サーバー過負荷、データベース遅延、ネットワーク混雑、過剰なリクエスト、非効率なスクリプトがあります。
404 エラーは、ファイル欠落、誤った URL、削除されたルート、不正なリライト規則、壊れたリンクを示すことがあります。500 エラーは、サーバー側コード障害、データベース問題、権限問題、または設定ミスのあるバックエンドサービスを示すことがあります。
認証失敗には、期限切れトークン、欠落した Cookie、誤った認証情報、ブロックされたクロスオリジン設定、不正なヘッダー処理が関係する場合があります。
リクエスト-レスポンスの経路を理解すると、問題が発生した場所を特定しやすくなります。
実用的なトラブルシューティング方法
まず URL とリクエストメソッドを確認します。次にステータスコードを調べます。その後、リクエストヘッダー、レスポンスヘッダー、Cookie、レスポンス本文を確認します。ブラウザの開発者ツールはこの作業に役立ちます。
サーバー側の問題では、アクセスログ、エラーログ、アプリケーションログ、リバースプロキシログ、バックエンドサービスの状態を確認します。分散システムでは、トレース ID とリクエスト ID が、複数サービスをまたいで 1 つのリクエストを追跡するのに役立ちます。
性能問題では、DNS 時間、接続時間、TLS 時間、サーバー応答時間、コンテンツダウンロード時間、キャッシュ動作、リソースサイズを確認します。これらの詳細により、問題がネットワーク関連、サーバー関連、またはフロントエンド関連かを判断できます。
このモデルが重要であり続ける理由
HTTP の動作原理が重要であり続けるのは、ほぼすべての現代的なデジタルサービスがそれに依存しているからです。Web サイト、API、モバイルアプリ、クラウドダッシュボード、管理プラットフォーム、決済システム、ログインサービス、監視システム、IoT プラットフォームは、すべて同じ基本概念、つまり要求、処理、応答を使います。
その強みは、単純さ、拡張性、可読性、幅広い互換性にあります。一貫した通信構造を保ちながら、多くの種類のコンテンツを運び、多くの種類のアプリケーションを支援できます。
同時に、優れた設計には、セキュリティ、キャッシュ、ヘッダー、ステータスコード、エラー処理、バージョン互換性、ネットワークアーキテクチャへの配慮が必要です。
まとめ
HTTP は、クライアントがサーバーに構造化されたリクエストを送り、構造化されたレスポンスを受け取ることで機能します。この単純なモデルの周囲に、現代の Web システムは DNS、TLS、キャッシュ、プロキシ、CDN、API、認証、性能最適化、セキュリティ制御を追加しています。
よくある質問
HTTP と HTTPS は同じですか?
いいえ。HTTP はメッセージ交換モデルを定義し、HTTPS は転送中の通信を保護するために TLS 暗号化と証明書ベースの身元確認を追加します。
なぜ 1 つの Web ページが多くのリクエストを発生させるのですか?
ページは通常、画像、スクリプト、スタイルシート、フォント、API 呼び出し、メディアリソースなどの個別ファイルに依存します。ブラウザはメイン文書を読んだ後、それらのリソースを要求します。
ブラウザなしで HTTP を使えますか?
はい。モバイルアプリ、サーバー、コマンドラインツール、IoT デバイス、監視システム、API は、従来の Web ブラウザなしで HTTP を使用できます。
なぜ一部の API 呼び出しは Web ページではなくデータを返すのですか?
API はしばしば JSON や XML などの構造化データを返します。受信側プログラムは、それを Web ページとして表示するのではなく処理します。
HTTP リクエストが失敗したとき、最初に何を確認すべきですか?
URL、リクエストメソッド、ステータスコード、ヘッダー、認証状態、ネットワーク接続、サーバーログ、そしてプロキシやゲートウェイがリクエストを変更していないかを確認します。