ロードバランシング(負荷分散)とは、トラフィックやサービスリクエスト、計算タスク、通信負荷を複数のリソースに分散し、特定のサーバーやアプリケーション、ゲートウェイ、ネットワーク経路だけが過負荷にならないようにする仕組みです。
概念の理解
現代のデジタルシステムでは、ユーザーはWebサイトやアプリケーション、コミュニケーションプラットフォーム、データベース、クラウドサービスに対して、ピーク時でも高速に応答し、常に利用可能であることを期待しています。すべてのリクエストを1台のサーバーや1つのコンポーネントに送信すると、そのリソースが低速になったり不安定になったり、ダウンしたりします。ロードバランシングは、利用可能な複数のリソースに作業を分散することでこの問題を解決します。ロードバランサーはトラフィックの交通整理役として機能し、受信したリクエストを、設定されたルールやアルゴリズムに従って最適なバックエンドリソースに転送します。バックエンドリソースには、Webサーバー、アプリケーションサーバー、データベースノード、メディアサーバー、SIPサーバー、クラウドインスタンス、コンテナ、ゲートウェイ、ネットワークリンクなどがあります。
ロードバランシングは単なる速度向上だけではありません。サービスの可用性を維持し、予測可能性を高め、需要の変化に応じて拡張しやすくすることも目的です。
プロセスの仕組み
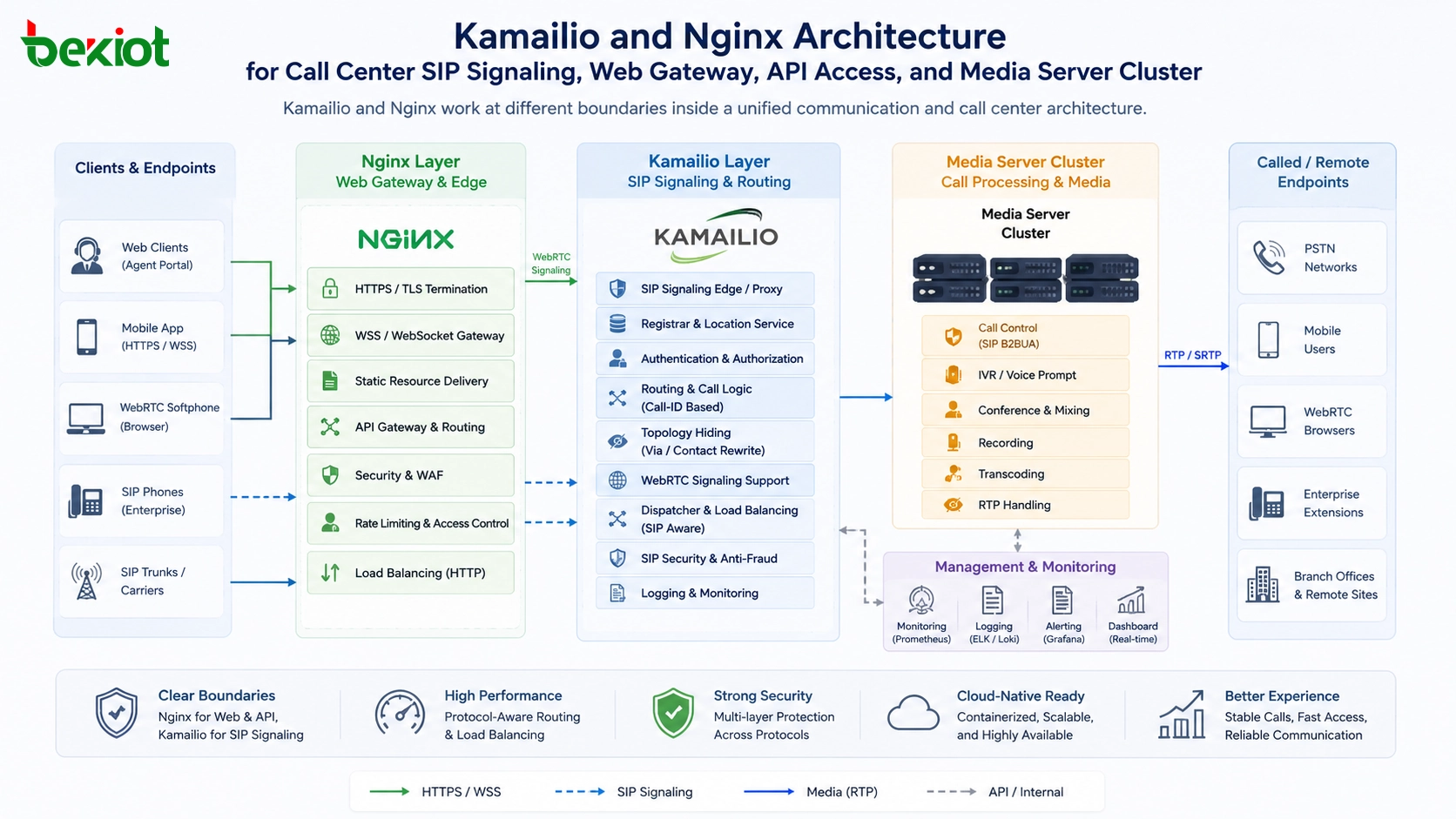
共有アクセスポイントからトラフィックが入る
ユーザーやデバイスは通常、単一のサービスアドレス、ドメイン名、仮想IP、ゲートウェイアドレス、またはアプリケーションエンドポイントに接続します。このアクセスポイントの背後には、リクエストを処理する準備ができている複数のバックエンドシステムがあります。ユーザーは実際にどのサーバーがリクエストを処理しているかを知る必要はありません。
この設計により、アクセスがシンプルになる一方で、管理者には柔軟性がもたらされます。顧客、従業員、アプリケーション、接続デバイスが使用するアドレスを変更することなく、バックエンドサーバーを追加、削除、更新、隔離できます。
ロードバランサーがバックエンドの状態を評価する
優れたロードバランシングシステムは、トラフィックをやみくもに転送しません。バックエンドリソースが正常に動作し、応答可能で、到達可能であり、新しいトラフィックを受け取る資格があるかどうかを確認します。ヘルスチェックには、単純なpingテスト、ポートチェック、HTTPステータスチェック、アプリケーションレベルのプローブ、カスタム監視スクリプトなどが含まれます。
バックエンドサーバーがヘルスチェックに失敗した場合、ロードバランサーはそのサーバーへのトラフィック送信を一時的に停止できます。これにより、ユーザーが故障または過負荷のリソースに誘導されるのを防ぎます。
ポリシーに基づいてリクエストを分散
バックエンドの状態を確認した後、ロードバランサーは各リクエストの送信先を選択します。決定は、ラウンドロビン順、サーバーの重み、アクティブ接続数、応答時間、地理的位置、セッション維持、アプリケーションコンテンツ、またはカスタムルールに基づいて行われます。
シンプルなシステムでは、基本的な分散ルールで十分かもしれません。トラフィックが多いシステムやビジネスクリティカルなシステムでは、アプリケーションの健全性、ユーザーセッション、サービス優先度、セキュリティ検査、フェイルオーバー動作などを考慮したポリシーが必要になる場合があります。
典型的なロードバランシングの流れ
基本的なロードバランシングプロセスは、トラフィックを制御し、バックエンドリソースを保護する4段階のワークフローとして理解できます。
一般的な分散方式
ラウンドロビン
ラウンドロビンは、バックエンドリソースに順番にリクエストを送信する方式です。シンプルで理解しやすく、バックエンドサーバーの能力が同程度で、リクエストの複雑さが比較的均衡している場合に適しています。
ただし、サーバー間で性能差がある場合や、処理時間が極端に異なるリクエストがある場合には理想的ではありません。そのような場合は、より適応的な方式が必要です。
最小コネクション数
最小コネクション方式は、アクティブな接続数が最も少ないバックエンドリソースに新しいリクエストを送信します。データベース接続や長時間のHTTPセッション、メディアストリーム、リアルタイム通信サービスのように、セッションの継続時間が異なる場合に有効です。
この方式は、1台のサーバーに長時間セッションが集中し、他のサーバーが十分に活用されない状況を回避するのに役立ちます。
重み付けバランシング
重み付けロードバランシングは、バックエンドリソースごとに異なるトラフィックの割合を割り当てます。より高性能なサーバーには多くのリクエストが送られ、低スペックや旧型のサーバーには少ないリクエストが送られます。ハードウェア、クラウドインスタンス、仮想マシンの性能が異なる場合に実用的です。
重みは移行時にも使用できます。管理者はまず新しいバージョンに少量のトラフィックを送り、安定性を確認してから徐々にその割合を増やすことができます。
コンテンツおよびアプリケーションを意識したルーティング
より高度なロードバランサーは、リクエスト情報を検査し、URLパス、ヘッダー、Cookie、プロトコル、テナントID、アプリケーションタイプ、サービスカテゴリに基づいてトラフィックをルーティングできます。これはWebプラットフォーム、マイクロサービス、API、クラウドネイティブシステムでよく使われます。
例えば、静的コンテンツはあるサーバーグループに、APIリクエストは別のグループに、リアルタイム通信トラフィックは専用のメディアサービスにと、振り分けることができます。これによりアーキテクチャの柔軟性と効率が向上します。
主な機能
ヘルスチェックとフェイルオーバー
ヘルスチェックにより、ロードバランサーはバックエンドリソースがまだリクエストを処理できるかどうかを検出できます。サーバーに障害が発生した場合、トラフィックは自動的に他のリソースに切り替えられます。これにより、1台のサーバー障害がサービス全体の中断につながるのを防ぎ、可用性が向上します。
フェイルオーバー動作は慎重にテストする必要があります。管理者は、システムが障害を検出する速度、既存のセッションへの影響、障害が復旧したリソースにトラフィックが戻る方法を把握しておく必要があります。
セッション維持
一部のアプリケーションでは、セッション中にユーザーが同じバックエンドサーバーに接続し続ける必要があります。これはセッションパーシスタンス、スティッキーセッション、またはセッションアフィニティと呼ばれ、Cookie、送信元IPアドレス、トークン、アプリケーション識別子に基づいて実現されます。
セッション維持は、一時的なセッション状態をローカルに保存するアプリケーションで役立ちます。ただし、多くのユーザーが1つのバックエンドリソースに固定されるとトラフィック分散効率が低下する可能性があるため、注意して使用する必要があります。
SSL終端
多くのロードバランサーは、フロントエンドでSSLまたはTLS暗号化を処理できます。つまり、クライアントからの暗号化トラフィックは、バックエンドサーバーに転送される前にロードバランサーで復号されます。SSL終端により、証明書管理が簡素化され、バックエンドシステムの暗号化負荷が軽減されます。
機密性の高い環境では、ロードバランサーとバックエンドサーバー間のトラフィックも暗号化されたままになる場合があります。適切な設計は、セキュリティ要件、ネットワーク信頼境界、コンプライアンス規則、パフォーマンスニーズによって異なります。
障害が発生したリソースや正常でないリソースからトラフィックを迂回させ、部分的な障害時でもサービスに到達できるようにします。
リクエストを複数のリソースに分散し、個々のサーバーへの負荷を軽減して応答の安定性を向上させます。
需要の増加に応じて、新しいサーバー、ノード、サービスインスタンスをロードバランサーの背後に追加できます。
主な利点
サービス信頼性の向上
ロードバランシングは、単一リソースがサービス提供の唯一のポイントになるのを防ぐことで信頼性を向上させます。1台のバックエンドサーバーが利用不能になっても、正常なサーバーがトラフィックの受け入れを継続できます。
これは完全な高可用性設計を代替するものではありませんが、その重要な一部です。信頼性の高いサービスには、冗長化されたロードバランサー、複数のネットワーク経路、レプリケートされたデータベース、バックアップ電源、監視、災害復旧計画も必要になる場合があります。
ユーザーエクスペリエンスの向上
トラフィックが効果的に分散されると、ユーザーはページ表示の遅延、リクエスト失敗、セッション切断、サービス過負荷といった状況に遭遇しにくくなります。これは、Webサイト、オンラインプラットフォーム、顧客ポータル、クラウドアプリケーション、コミュニケーションサービス、社内業務システムにとって重要です。
ユーザーエクスペリエンスはピーク時に特に影響を受けやすくなります。通常トラフィックでは正常に動作するシステムも、キャンペーン、製品発表、季節変動、公共イベント、予期せぬインシデントによって機能不全に陥ることがあります。
より柔軟なメンテナンス
ロードバランシングにより、プラットフォーム全体をシャットダウンすることなく、バックエンドリソースをサービスから外して更新、テスト、復帰させることができるため、メンテナンスが容易になります。管理者は、あるサーバーからトラフィックを排出し、他のサーバーがユーザー対応を継続できます。
これは、ソフトウェアアップグレード、セキュリティパッチ適用、ハードウェア交換、構成変更、新バージョンの段階的デプロイに役立ちます。
代表的な用途
WebサイトとWebアプリケーション
Webプラットフォームでは、HTTPおよびHTTPSトラフィックを複数のWebサーバーまたはアプリケーションサーバーに分散するためにロードバランシングが一般的に使用されます。これにより、より多くの訪問者を処理し、応答性を維持し、単一サーバー障害時のダウンタイムを回避できます。
最新のWebアプリケーションでは、API呼び出し、静的アセット、ユーザーセッション、マイクロサービスリクエストをアプリケーションルールに基づいて異なるバックエンドプールにルーティングすることもあります。
クラウドとコンテナ環境
クラウドプラットフォームとコンテナシステムは、サービスインスタンスを動的に作成、置換、スケール、移動できるため、ロードバランシングに大きく依存しています。ロードバランサーは、バックエンドリソースが頻繁に変更されても安定したアクセスポイントを提供します。
コンテナオーケストレーション環境では、Ingressコントローラ、サービスメッシュルーティング、ノードレベルバランシング、外部クラウドロードバランサーなど、複数のレベルでロードバランシングが機能する場合があります。
コミュニケーションサービスとメディアサービス
コミュニケーションプラットフォームでは、SIPシグナリング、メディアサービス、会議システム、メッセージングゲートウェイ、録音サービス、APIアクセスにロードバランシングが使われることがあります。設計では、プロトコルの振る舞い、セッション維持、NAT越え、レイテンシ、リアルタイムメディア品質を考慮する必要があります。
音声やビデオサービスでは、通常のWeb型バランシングでは不十分な場合があります。管理者は、ロードバランサーが関連プロトコルを理解しているか、メディアパスに特別な処理が必要かどうかを確認する必要があります。
データベースと内部プラットフォーム
データベースロードバランシングでは、読み取りトラフィックの分散、利用可能なデータベースレプリカへのアプリケーションの誘導、ノード間のフェイルオーバーをサポートできます。企業内プラットフォームでは、認証システム、ファイルサービス、監視プラットフォーム、ビジネスアプリケーションにもロードバランシングが利用されます。
データベースバランシングには慎重な計画が必要です。データの一貫性、書き込みルーティング、レプリケーション遅延、トランザクション動作がアプリケーションの正確性に影響を与える可能性があるからです。
計画時の考慮事項
適切なレイヤーを選ぶ
ロードバランシングは異なるレイヤーで動作します。レイヤー4バランシングは主にIPアドレスとポートを扱い、レイヤー7バランシングはHTTPヘッダー、URL、Cookie、リクエストコンテンツなどのアプリケーションレベルの情報を理解します。
レイヤー4は一般的なトラフィックに対して高速かつ効率的です。レイヤー7は、WebアプリケーションやAPI、アプリケーションを意識したポリシーに対してよりインテリジェントなルーティングを提供します。正しい選択は、プロトコルタイプ、パフォーマンス要件、セキュリティ検査、ルーティングの複雑さによって決まります。
隠れた単一障害点を回避する
多数のサーバーの前に1台のロードバランサーを配置するとバックエンド分散は改善されますが、ロードバランサー自体が冗長化されていないと単一障害点になる可能性があります。クリティカルなシステムでは、アクティブ/パッシブまたはアクティブ/アクティブのロードバランサーペアがよく使われます。
ネットワーク経路、DNS、証明書、ファイアウォールルール、監視システム、管理アクセスも見直す必要があります。アクセス経路が脆弱であれば、いくらバックエンドプールが高可用でも不十分です。
実際のパフォーマンスを監視する
ロードバランシングは継続的に監視されるべきです。重要なメトリクスには、リクエスト数、応答時間、エラー率、アクティブ接続数、バックエンドの正常性、帯域幅使用量、CPU負荷、メモリ使用量、キュー長、ヘルスチェック失敗数が含まれます。
レポートは、管理者がアルゴリズムを調整し、バックエンド容量を調整し、ボトルネックを特定し、スケールアウトのタイミングを判断するのに役立ちます。監視がなければ、ロードバランシングはユーザーから苦情が出るまで問題を隠してしまう可能性があります。
実践的な設計上の注意
ロードバランサーを魔法のようなパフォーマンス改善策として扱うべきではありません。ロードバランサーが最も効果を発揮するのは、バックエンドシステムが健全であり、監視がアクティブで、キャパシティ計画が現実的で、実際の障害発生前にフェイルオーバー動作がテストされている場合です。
メンテナンスのヒント
ヘルスチェック設定を見直す
ヘルスチェックは実際のサービス可用性を反映すべきです。単純なpingに応答しても、アプリケーション自体が障害を起こしている可能性があります。アプリケーションレベルのチェックは、サービスが意味のある作業を実行できることを確認するため、より有用です。
ヘルスチェックの間隔と障害しきい値も調整する必要があります。あまりに積極的なチェックは、短時間の遅延で正常なサーバーを除外してしまう可能性があり、逆に遅すぎるチェックは、障害が起きたリソースにトラフィックを送り続ける可能性があります。
フェイルオーバーと復旧をテストする
フェイルオーバー動作は、本番インシデントで発見するのではなく、計画メンテナンス中にテストすべきです。チームは、バックエンドサーバーが故障した場合、ロードバランサーが故障した場合、ネットワーク経路が切断された場合、復旧したサーバーがプールに再参加する場合に何が起こるかを検証する必要があります。
テストには、技術的メトリクスとユーザーへの影響の両方を含めるべきです。ログ上では成功しているように見えるフェイルオーバーでも、状態処理が適切に設計されていないと、セッション切断やアプリケーションエラーが発生する可能性があります。
証明書とポリシーを最新に保つ
ロードバランサーがSSL終端を処理する場合、証明書の有効期限は慎重に管理する必要があります。期限切れの証明書は、正常なサービスをユーザーから見て利用不能に見せてしまいます。セキュリティポリシー、暗号スイート設定、アクセスルール、ログ設定も定期的に見直す必要があります。
規制対象環境では、管理者は証明書の変更、アクセスポリシーの更新、トラフィック処理ルールを監査やトラブルシューティングのために文書化すべきです。
よくある質問
ロードバランシングはセキュリティを向上させますか?
SSL終端、アクセス制御、トラフィックフィルタリング、Webアプリケーションファイアウォール統合、レート制限、ログ記録などの機能と組み合わせることでセキュリティを支援できます。ただし、単体で完全なセキュリティソリューションとして扱うべきではありません。
ロードバランシングとフェイルオーバーの違いは何ですか?
ロードバランシングは通常のトラフィックを複数のリソースに分散します。フェイルオーバーは、障害が発生したリソースから別の利用可能なリソースにトラフィックを移動します。多くのシステムが両方を使用しますが、それぞれがサービス信頼性の異なる側面を解決します。
小規模なWebサイトすべてにロードバランサーが必要ですか?
必ずしもそうではありません。トラフィックの少ない小規模サイトは、単一サーバーで十分に動作する場合があります。ロードバランシングは、可用性、トラフィック増加、メンテナンスの柔軟性、パフォーマンス安定性が重要になったときに有用になります。
設定を誤るとロードバランシングが問題を引き起こすことはありますか?
はい。不適切なセッション維持、脆弱なヘルスチェック、誤ったルーティングルール、証明書エラー、不均等なバックエンド重み付けは、ログイン失敗、トランザクション中断、サービスループ、誤ったサーバーへのトラフィック集中を引き起こす可能性があります。
ロードバランシングルールはどのくらいの頻度で見直すべきですか?
アプリケーションの大幅変更、トラフィック増加、サーバー交換、クラウド移行、証明書更新、パフォーマンスに関する繰り返しの苦情の後にはルールを見直すべきです。クリティカルなサービスでは、定期的な見直しを通常運用の一部に組み込む必要があります。