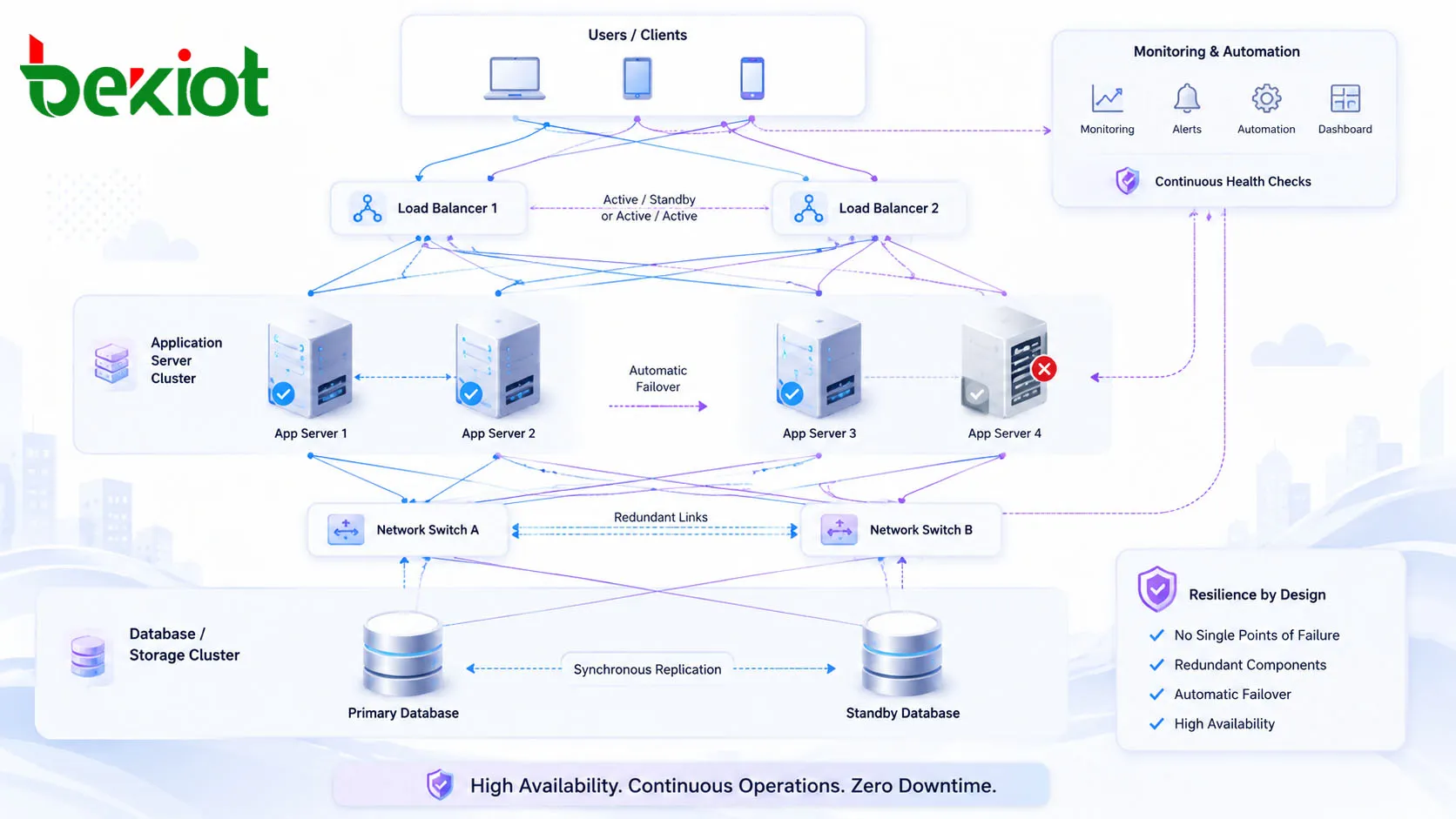
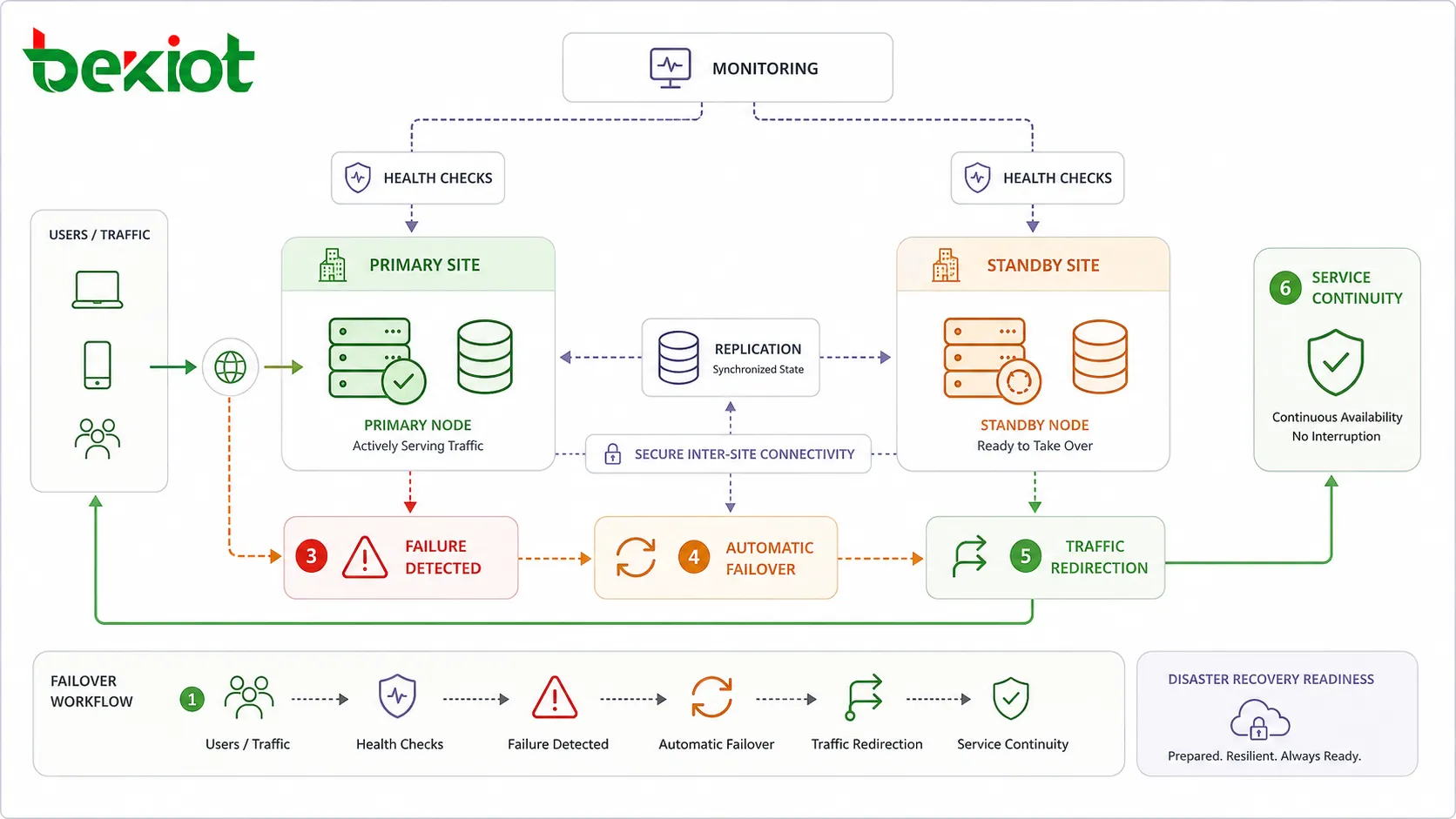
High availability is a design approach that keeps a system, service, application, or network accessible even when individual components fail. Instead of depending on one server, one database, one network path, one power source, or one software process, a highly available system uses redundancy, monitoring, failover, and recovery planning to reduce downtime and maintain service continuity.
For businesses and organizations that depend on digital operations, high availability is not only an IT concept. It affects customer experience, production efficiency, emergency response, communication reliability, data access, security operations, and service-level commitments. A short interruption may be acceptable for a low-priority internal tool, but the same interruption can be unacceptable for a hospital system, dispatch platform, payment gateway, industrial control network, public communication service, or cloud application used by thousands of users.
Meaning in Practical System Design
High availability, often abbreviated as HA, refers to the ability of a system to stay usable for a high percentage of time. It is commonly discussed through uptime targets such as 99.9%, 99.99%, or 99.999%. However, availability is not only about whether a server is powered on. A system is truly available only when users can complete the actions they need, such as placing a call, submitting a transaction, opening an application, receiving an alarm, synchronizing records, or accessing real-time information.
A reliable service depends on the complete service chain. This may include compute resources, storage, database engines, network switches, firewalls, DNS, identity services, security certificates, application processes, monitoring tools, backup links, power infrastructure, and operational procedures. If one critical dependency has no backup path, the entire service may still be vulnerable.
High availability is also different from ordinary backup. A backup helps restore data after a failure, but it may not keep the service running during the failure. HA focuses on continuity. It allows another node, path, service instance, or site to take over before users experience a long interruption.
Why Organizations Build for Continuity
The value of high availability becomes clear when downtime creates real consequences. In e-commerce, downtime can mean lost orders and payment failures. In telecommunications, it can mean missed calls, unreachable extensions, or interrupted emergency routing. In manufacturing, it can stop production workflows. In healthcare and public safety, it can delay communication, coordination, and response.
Availability also protects trust. Customers, employees, partners, and field teams expect modern systems to be accessible at any time. When a platform goes offline repeatedly, users may lose confidence even if each outage is short. For service providers and enterprise platforms, stable uptime is part of the overall product experience.
Another reason is operational control. Without HA planning, technical teams often rely on emergency troubleshooting after a failure has already affected users. With redundancy, automated health checks, failover logic, and clear incident procedures, failures become controlled events rather than unexpected crises.
A highly available system does not assume that failures will never happen. It assumes that failures will happen and prepares the service to continue operating when they do.
Core Features That Support Reliable Operation
Redundant Infrastructure
Redundancy is the foundation of high availability. Important components are duplicated so that another component can continue working if the active one fails. Redundancy can include multiple servers, clustered application nodes, mirrored storage, replicated databases, dual power supplies, backup routers, redundant switches, multiple internet connections, and duplicated service instances across different locations.
Effective redundancy must cover the real service path. Two application servers do not provide full protection if both depend on one database, one storage array, one firewall, one power circuit, or one external provider. HA planning should review every dependency that the service needs to function.
Automatic Failover
Failover is the process of moving service from a failed component to a healthy component. In many HA designs, this process happens automatically. For example, a load balancer can remove an unhealthy server from rotation, a standby database can become the primary database, or a backup network route can take over when the main link is interrupted.
Automatic failover reduces recovery time because it does not wait for an engineer to diagnose the fault manually. However, failover logic must be carefully designed. If health checks are too simple, the system may switch unnecessarily. If failover rules are too slow, users may experience longer downtime than expected.
Service Health Monitoring
Monitoring allows the system and operations team to detect abnormal conditions early. Useful monitoring covers server health, CPU and memory usage, disk space, service response time, database replication, network latency, packet loss, call completion, transaction success rate, certificate expiration, backup status, and security events.
The most useful health checks are connected to real service behavior. A device may respond to ping while the application is frozen. A web server may be running while the database connection is broken. A communication server may be online while call routing is failing. Monitoring should confirm whether the service is actually usable.
Load Distribution
Load balancing distributes traffic across multiple servers or service instances. This improves performance during normal operation and supports continuity during faults. If one node becomes overloaded or unavailable, traffic can be shifted to other healthy nodes.
Load balancing is widely used for websites, APIs, cloud applications, communication platforms, authentication services, and internal enterprise systems. Depending on the design, it may support session persistence, geographic routing, health-based routing, or application-aware traffic steering.
Data Replication
Many systems cannot remain available unless data is available too. Data replication keeps copies of important information across multiple nodes or locations. This allows a secondary server, storage system, or data center to continue service if the primary environment fails.
Replication can be synchronous or asynchronous. Synchronous replication confirms a write only after data is written to more than one place, which can improve consistency but may increase latency. Asynchronous replication is usually faster, but a small amount of recent data may be at risk if a sudden failure occurs. The right choice depends on the required balance between performance, consistency, and acceptable data loss.
Maintenance Without Full Shutdown
A good HA design also helps during planned maintenance. Systems need updates, security patches, hardware replacement, certificate renewal, configuration changes, and capacity expansion. If the architecture supports rolling updates or controlled failover, maintenance can be completed without taking the entire service offline.
This is especially useful for services that operate around the clock. Instead of waiting for long maintenance windows, teams can update one node at a time while other nodes continue handling production traffic.
Common Architecture Patterns
Active-Standby
In an active-standby design, one system handles production traffic while another system remains ready to take over. This model is often used for firewalls, databases, PBX systems, gateways, industrial applications, and core management platforms.
The advantage of active-standby architecture is simplicity and predictable failover behavior. The disadvantage is that standby resources may not be fully used during normal operation. The standby system must also be regularly tested to confirm that it is synchronized and ready.
Active-Active
In an active-active design, multiple systems handle traffic at the same time. If one node fails, the remaining nodes continue running and absorb the workload. This model can improve both availability and performance because capacity is used continuously.
Active-active architecture usually requires more careful design. Applications must handle distributed sessions, data consistency, routing behavior, and possible conflict scenarios. If the software is not designed for distributed operation, active-active deployment can create complexity instead of reliability.
Clustered Services
A cluster is a group of nodes that work together as one service. Clustered systems can protect applications, databases, virtual machines, storage platforms, container workloads, and communication services. Cluster managers monitor node health and coordinate failover or workload redistribution.
Stable clustering requires proper heartbeat communication, quorum rules, fencing mechanisms, and network separation. These controls help prevent split-brain situations, where two nodes incorrectly believe they are both the primary system.
Multi-Site Deployment
For higher resilience requirements, systems may be deployed across multiple sites, data centers, cloud availability zones, or regions. If one site becomes unavailable because of power failure, network outage, physical damage, or a major infrastructure incident, another site can continue service.
Multi-site design is more complex than local redundancy. It requires traffic steering, secure connectivity, replication planning, consistent configuration, operational coordination, and regular disaster recovery tests. It also requires clear rules for when to switch traffic between sites.
Metrics Used to Measure Service Continuity
Uptime Percentage
Uptime percentage measures how long a system remains operational during a specific period. It is often used in service-level agreements and internal reliability targets. Higher uptime targets require stronger architecture, faster recovery, better monitoring, and more disciplined operations.
However, uptime should be measured from the user’s perspective. A system that is technically running but unable to process requests, complete calls, access data, or respond within acceptable time limits should not be considered fully available.
Recovery Time Objective
Recovery Time Objective, or RTO, defines how quickly service should be restored after an interruption. A short RTO usually requires automated failover, ready-to-use standby capacity, tested procedures, and fast detection.
RTO should match business impact. Not every system needs immediate recovery. Some internal systems can tolerate a longer recovery period, while mission-critical services may require near-continuous operation.
Recovery Point Objective
Recovery Point Objective, or RPO, defines how much data loss is acceptable after a failure. A low RPO requires frequent or continuous replication. A higher RPO may allow recovery from scheduled backups.
RPO matters for transaction records, call logs, event histories, production data, user information, audit trails, and operational reports. If data loss is unacceptable, replication and backup design must be stricter.
Mean Time to Repair
Mean Time to Repair, or MTTR, measures how long it takes to restore normal service after a failure. High availability improves when MTTR is reduced. Better automation, clearer documentation, trained operators, spare resources, and tested recovery plans all help shorten repair time.
Reducing repair time is often more realistic than trying to prevent every possible failure. Even well-designed systems will fail eventually, but a well-prepared organization can recover faster and with less user impact.
Applications in Real-World Environments
Cloud Platforms and SaaS Applications
Cloud services and SaaS platforms use HA design to keep applications accessible to users across different locations and time zones. Common techniques include auto-scaling groups, load balancers, replicated databases, distributed object storage, health checks, backup regions, and rolling deployment strategies.
For subscription-based services, availability directly affects customer retention and brand reputation. Users may not know the details of the architecture, but they quickly notice slow responses, login failures, missing data, or service interruptions.
Enterprise Communication Systems
Voice, video, messaging, paging, and dispatch systems often require high availability because communication may be needed during routine work as well as urgent incidents. HA planning can include redundant call servers, backup SIP trunks, secondary gateways, resilient network paths, survivable branch systems, and backup power.
Communication availability should be tested from endpoint to endpoint. It is not enough for a server to be online if phones cannot register, calls cannot be routed, audio cannot pass through the network, or emergency numbers cannot be reached.
Industrial and Energy Operations
Industrial sites, utilities, mining operations, ports, transportation hubs, and energy facilities often depend on continuous monitoring and communication. In these environments, high availability may include redundant fiber rings, backup wireless links, dual control servers, local survivability, ruggedized equipment, and isolated emergency paths.
The design must consider both IT failures and physical conditions. Harsh environments, electromagnetic interference, remote locations, power instability, and limited maintenance access can all affect availability.
Healthcare and Emergency Services
Hospitals, emergency response centers, public safety agencies, and command rooms rely on reliable systems for coordination. High availability can support patient information access, alarm notification, emergency communication, dispatch workflows, access control, video monitoring, and internal collaboration.
In these environments, downtime is not only a technical issue. It can affect response speed, safety, decision-making, and continuity of care. Backup power, redundant networks, clear escalation procedures, and regular drills are especially important.
Finance, Retail, and Online Transactions
Banks, payment processors, trading platforms, and online stores require reliable systems to protect transactions and customer access. Even short outages can cause failed payments, lost sales, delayed orders, settlement issues, or customer complaints.
These systems often combine availability planning with strong security, audit logging, fraud monitoring, encryption, and compliance controls. Service continuity must be designed together with data integrity and risk management.
Design Considerations Before Deployment
Map the Full Dependency Chain
The first step is to understand how the service actually works. Teams should map applications, databases, networks, storage, authentication, DNS, firewalls, third-party services, certificates, monitoring tools, and operational responsibilities. This helps identify hidden dependencies that could become single points of failure.
A service map also helps teams decide which components need redundancy and which risks can be accepted. Not every dependency requires the same protection level, but every critical dependency should be visible.
Set Realistic Recovery Targets
Availability targets should be based on business needs, not on marketing language. A mission-critical platform may justify expensive redundancy and near-real-time replication. A low-priority reporting tool may only need scheduled backup and manual recovery.
Clear RTO and RPO targets help teams choose the right architecture. They also help avoid overengineering systems that do not need advanced protection or underprotecting services that are essential to operations.
Test Failover Under Controlled Conditions
A failover plan is only valuable if it works when needed. Controlled tests verify whether monitoring detects the failure, standby resources activate correctly, traffic redirects as expected, data remains consistent, and users can continue working.
Testing should include planned failover, node failure simulation, network isolation, backup restoration, database recovery, and rollback procedures. Results should be documented so that future improvements are based on evidence rather than assumptions.
Control Configuration Changes
Many outages are caused by human error rather than hardware failure. Incorrect firewall rules, expired certificates, incompatible updates, wrong routing changes, database permission errors, and inconsistent configuration can all interrupt service.
Change control, version management, approval workflows, test environments, rollback plans, and configuration backups reduce this risk. In HA environments, both primary and standby systems must remain aligned.
Challenges and Limitations
High availability reduces downtime, but it does not make a system failure-proof. Software bugs, ransomware, configuration mistakes, data corruption, dependency outages, regional disasters, and operator errors can still disrupt service. HA should work together with backup, cybersecurity, disaster recovery, observability, and incident response.
Cost is another challenge. Redundant architecture may require more servers, network devices, cloud resources, licenses, monitoring systems, storage capacity, and operational expertise. The higher the availability target, the more important it becomes to justify the investment.
Complexity can also become a risk. A complicated HA design that the operations team does not understand may fail during an incident. Practical high availability should be documented, testable, and manageable by the people responsible for running it.
The best availability strategy is not always the most complex one. It is the one that protects the most important services, can be tested regularly, and can be operated confidently during real incidents.
Best Practices for Long-Term Reliability
Start with service classification. Identify which systems are mission-critical, which are business-important, and which can tolerate longer recovery. This allows resources to be focused where downtime has the greatest impact.
Use monitoring that reflects real user outcomes. Instead of checking only device status, monitor whether users can log in, place calls, access records, submit forms, receive alerts, or complete transactions. This gives a more accurate view of service health.
Keep documentation current. Architecture diagrams, failover steps, contact lists, escalation paths, backup locations, credentials handling, and rollback procedures should be updated after every major change. During an incident, outdated documentation can delay recovery.
Review the architecture regularly. Traffic volume, software versions, security requirements, third-party dependencies, and business priorities change over time. A system that met availability goals in the past may need redesign as usage and risk increase.
Conclusion
High availability is a practical method for keeping important services accessible when failures occur. It combines redundant infrastructure, automatic failover, health monitoring, load balancing, data replication, maintenance planning, and tested recovery procedures. Its value is especially clear when downtime affects safety, revenue, communication, production, compliance, or customer trust.
A successful HA strategy is not simply about adding more equipment. It requires understanding the full service chain, identifying single points of failure, setting realistic recovery targets, testing failover, and balancing reliability with cost and complexity. When designed correctly, high availability helps organizations build systems that remain dependable under real-world conditions.
FAQ
Can a highly available system still lose data?
Yes. Availability and data protection are related but not identical. If replication is delayed or backup policies are weak, a service may recover quickly while still losing recent data. RPO planning is needed to control this risk.
Is high availability the same as fault tolerance?
No. Fault tolerance usually means a system continues operating with little or no interruption even when a component fails. High availability focuses on reducing downtime, but a brief failover delay may still occur depending on the architecture.
Should small businesses use high availability?
Yes, but the design should match the business impact. A small company may not need multi-region architecture, but it can still benefit from redundant internet links, reliable backups, cloud-based failover, monitored services, and backup power for critical systems.
Can high availability protect against cyberattacks?
Only partly. HA can help maintain service if one node is isolated or restored, but it cannot replace cybersecurity controls. Ransomware, credential theft, DDoS attacks, and data tampering require security monitoring, access control, patching, backup isolation, and incident response.
Does every application support active-active deployment?
No. Some applications are not designed for distributed sessions, shared state, or multi-node writes. Before choosing active-active architecture, teams should confirm that the software, database, licensing model, and network design can support it safely.