データベースの問題は、データベースの中だけで終わることはほとんどありません。唯一のデータコピーが遅くなったり、到達不能になったり、破損したり、過負荷になったりすると、その上で動く業務システムはすぐに影響を受けます。注文は登録できず、レポートは生成できず、端末は記録をアップロードできず、ユーザーはログインできず、復旧は時間との競争になります。
データベースレプリケーションは、そのために存在します。データの追加コピーを一つ以上作成し、元のデータベースと同期させ続けることで、システムはより速く読み取り、より速く復旧し、負荷を分散し、単一のデータベースノードだけでは足りない状況でも動作を継続できます。
データベースレプリケーションの基本的な考え方
データベースレプリケーションとは、一つのデータベースノードから別のノードへデータをコピーし、変更が発生するたびにそのコピーを更新し続ける仕組みです。元になるデータベースは、技術によってプライマリ、マスター、パブリッシャー、リーダーなどと呼ばれます。受け取る側は、レプリカ、スタンバイ、サブスクライバー、セカンダリ、フォロワーなどと呼ばれます。名称は異なっても、ある場所で発生した変更を制御された方法で別の場所へ届けるという目的は同じです。
コピー対象は、データベース全体、選択されたテーブル、パーティション、スキーマ、トランザクションログ、特定のデータストリームなどです。あるシステムではレプリカをバックアップやフェイルオーバーのためだけに使います。別のシステムでは、読み取り処理、分析、レポート、地域別アクセス、下流処理をレプリカに任せます。つまり、レプリケーションは一つの固定機能ではなく、運用目的に応じて使う設計手法です。
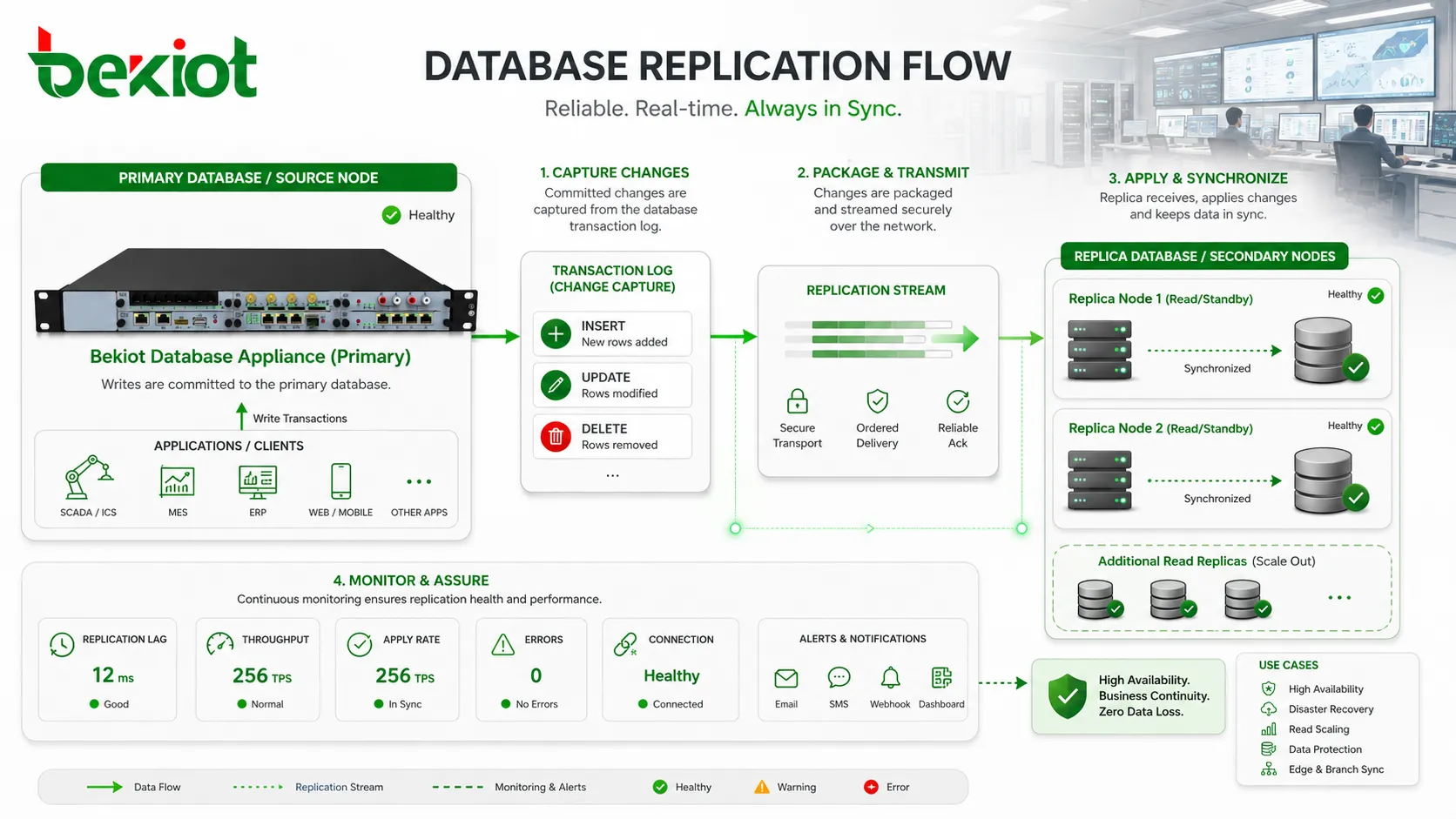
レプリケーションの中心には変更追跡があります。データが挿入、更新、削除されると、データベースはその変更を識別し、信頼できる形式にまとめ、別のノードへ送り、正しい順序で適用しなければなりません。この処理が雑であればレプリカは不整合になります。遅すぎればレプリカは遅延します。監視されていなければ、復旧が必要になった時点で初めて問題に気づくことになります。
優れたレプリケーション設計は、どのデータをコピーするのか、どれほど速く届く必要があるのか、誰が書き込めるのか、競合をどう扱うのか、ネットワーク障害時に何が起きるのか、ノードが使えないときアプリケーションがどう振る舞うのかを明確にします。これらの答えが、レプリケーションをレジリエンスの手段にするか、混乱の原因にするかを決めます。
データベースノード間で実際に移動するもの
レプリケーションは、単純なファイルコピーとは限りません。多くの本番システムでは、レコードが変わるたびに全データを送り直すことはありません。変更だけを取得し、その変更をレプリカ上で再現するために必要な情報だけを転送します。これにより帯域使用を抑え、最初から再構築しなくてもレプリカを元の状態に近づけられます。
一般的な方式の一つがログベースレプリケーションです。プライマリデータベースは、変更をトランザクションログ、バイナリログ、先行書き込みログ、REDOログなどに記録します。レプリカはそれらのログを読み取り、同じ操作を順番に適用します。ログにはデータベース変更の正式な順序が含まれているため、この方式は広く使われます。
もう一つの方式はステートメントベースレプリケーションです。SQL文をレプリカへ送る方式で、一部のシステムでは単純ですが、非決定的な関数、時刻値、乱数、環境依存の動作に依存する文では差異が生じる可能性があります。行ベースレプリケーションは、変更を生んだ文ではなく実際の行変更を送るため、多くの問題を避けられます。
スナップショットレプリケーションを使うシステムもあります。ある時点のデータ全体または一部のコピーを取得し、別の場所へ届けます。これは初期同期、レポート用データベース、定期的なデータ配布に有効です。ただし、ほぼリアルタイム更新が必要なシステムでは、スナップショットだけでは不十分です。
現代の構成では、変更データキャプチャ、つまりCDCも使われます。CDCはデータベースの変更を取り出し、分析基盤、検索インデックス、メッセージキュー、データレイクなどへ送ります。この場合、レプリケーションは単に別のデータベースコピーを保つだけでなく、組織のデータ移動パイプラインの一部になります。
日常運用におけるプライマリ・レプリカ構成
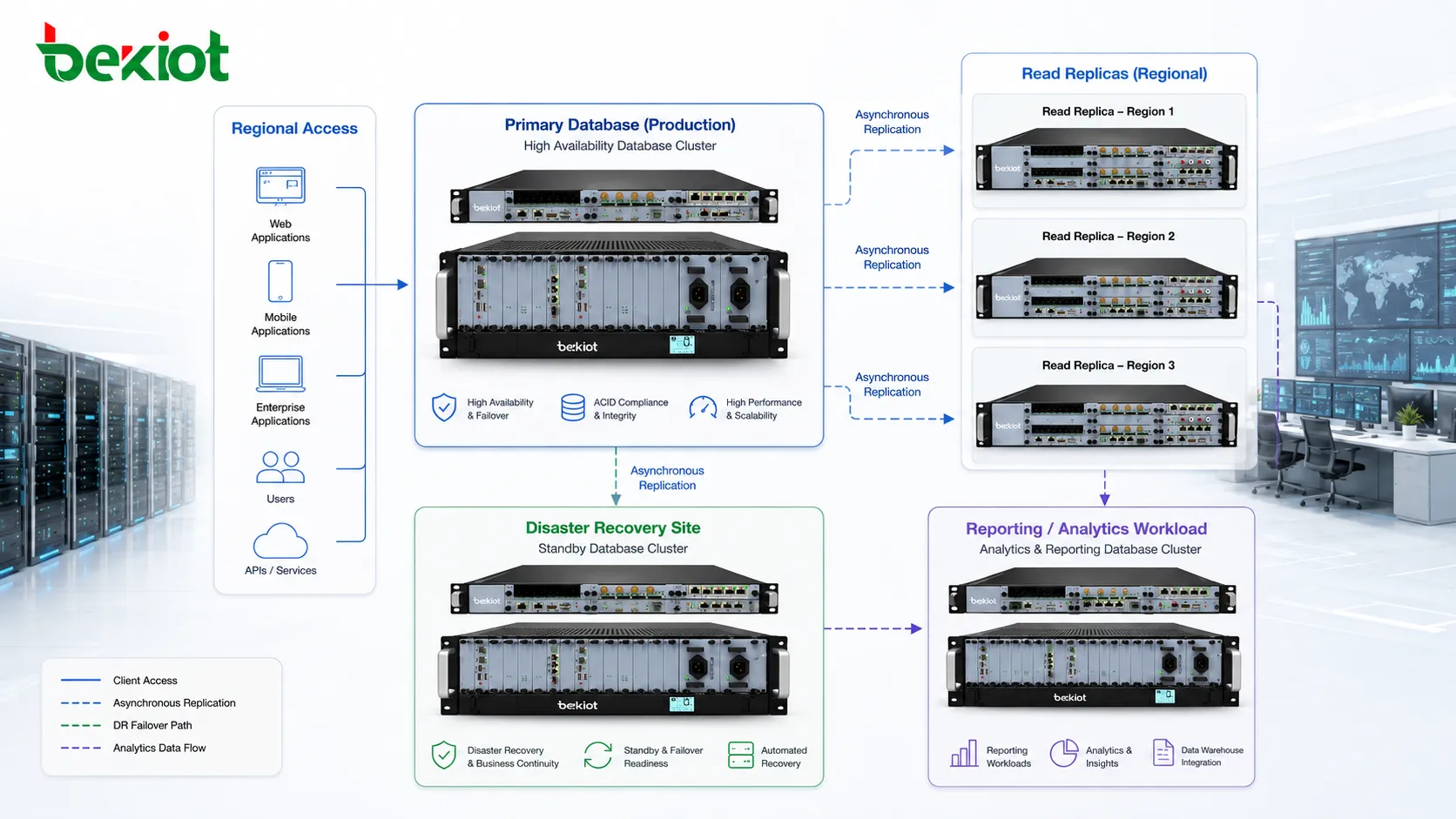
最も一般的なパターンは、プライマリ・レプリカ構成です。一つのデータベースノードが書き込みを受け付け、一つ以上のレプリカが変更のコピーを受け取ります。アプリケーションは挿入、更新、削除をプライマリへ送ります。読み取り専用クエリは、アプリケーションと設計が対応していればレプリカへ送ることができます。
このパターンは理解しやすく広く使われています。書き込みの所有権が明確だからです。プライマリが変更の正本であり、レプリカはその状態に従います。レプリカが故障してもプライマリは動き続けます。プライマリが故障した場合は、フェイルオーバー設計に従ってレプリカを新しいプライマリへ昇格できます。
利点は、実務上の負荷分離です。トランザクション書き込み、ユーザー操作、業務更新はプライマリに残し、レポート、ダッシュボード、検索、読み取りの多いサービスはレプリカを使えます。これにより主データベースの負荷を下げ、応答時間を改善できます。
ただし、特に非同期レプリケーションでは、レプリカが常に完全に最新とは限らないことをアプリケーションが理解する必要があります。プライマリへ書き込んだ直後に遅延しているレプリカから読むと、最新の変更が見えない場合があります。これは必ずしも障害ではなく、慎重に扱うべき設計上のトレードオフです。
マルチプライマリと分散レプリケーション
一部の環境では、書き込み可能なノードが複数必要になります。マルチプライマリレプリケーションでは、複数のノードが書き込みを受け付け、変更を相互に複製します。分散拠点、地域運用、ローカル書き込み、データセンター間の高可用性に役立ちますが、プライマリ・レプリカより複雑です。
最大の課題は競合です。二つのノードが同じレコードを同時に更新した場合、どちらの変更を採用するのか、またはどう統合するのかを決める必要があります。ルールはタイムスタンプ、バージョン番号、アプリケーションロジック、ノード優先度、手動判断などに基づきます。競合処理が悪いとデータ品質を損ないます。
分散レプリケーションは、エッジシステム、小売拠点、産業サイト、モバイルアプリ、遠隔業務でも使われます。中央ネットワークが不安定でもローカルデータを使い続けるためです。ローカルノードは一時的にデータを保存・更新し、後で中央と同期できます。これはローカル継続性を高めますが、同期ルールを厳密にする必要があります。
マルチプライマリ設計は、ビジネス上の必要性が複雑さを正当化する場合にだけ選ぶべきです。多くのアプリケーションでは、一つの書き込みプライマリと読み取りレプリカの方が運用しやすいです。複数拠点で本当にローカル書き込みが必要な場合は、競合管理、データ所有、監視を導入前に設計する必要があります。
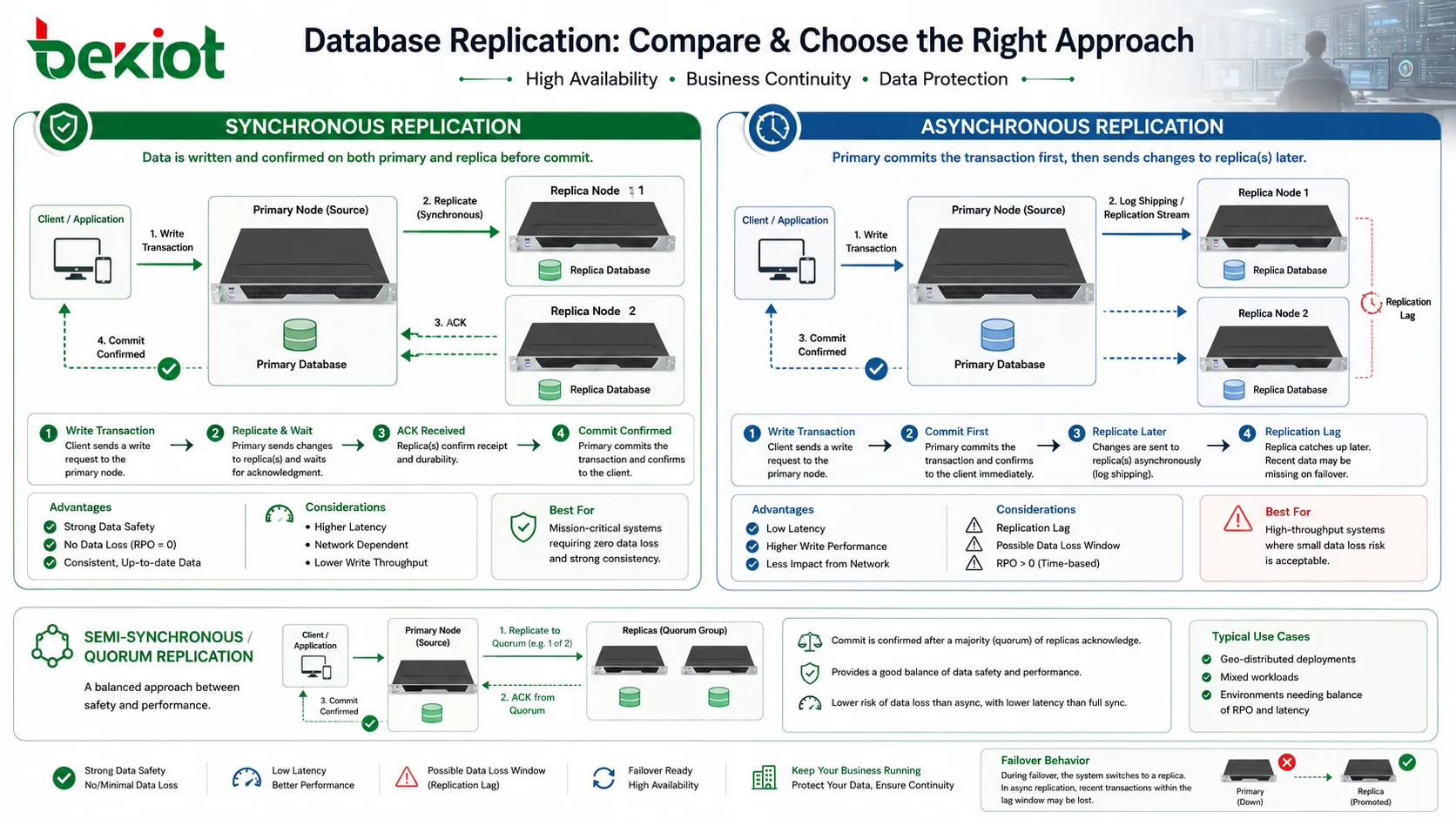
同期レプリケーションと非同期レプリケーション
レプリケーションのタイミングは重要な設計判断です。同期レプリケーションでは、別のデータベースノードが変更を確認するまで、トランザクションは完全にコミットされたと見なされません。これにより、アプリケーションに成功が返る前にレプリカが変更を持つため、データ安全性が高まります。コミット直後にプライマリが故障しても、確認済みデータが別ノードに存在する可能性が高くなります。
その代償は遅延です。レプリカが遠い、またはネットワークが遅い場合、プライマリはトランザクション完了まで長く待つ必要があります。これはアプリケーション応答に影響します。同期方式は、データ損失の許容度が低く、ノード間ネットワークが十分に信頼できる場合に使われます。
非同期レプリケーションでは、プライマリが先にトランザクションをコミットし、その後で変更をレプリカへ送ります。アプリケーションは遠隔確認を待たないため、書き込み性能は向上します。レポート、読み取り拡張、長距離の災害復旧でよく使われます。
トレードオフはレプリケーション遅延です。変更がレプリカへ届く前にプライマリが故障すると、最近の一部トランザクションが失われたり、ログからの復旧が必要になったりします。そのため、非同期方式は明確な復旧目標と合わせる必要があります。許容できるデータ損失と通常時の追いつき速度を決めておくべきです。
半同期方式やクォーラム方式を使うシステムもあります。これらは一つ以上のレプリカが確認した時点で成功を返し、すべてのレプリカを待つとは限りません。最適な方式は、業務リスク、ネットワーク品質、トランザクション量、復旧要件によって決まります。
可用性とフェイルオーバーの利点
レプリケーションの最も直接的な利点は可用性の向上です。プライマリデータベースが故障した場合、レプリカを昇格してサービスを継続できます。レプリケーションがなければ、復旧はバックアップ復元に頼ることになり、時間がかかり、より新しいデータを失う可能性があります。レプリケーションは、より速い復旧に使える稼働中またはほぼ稼働中のコピーを提供します。
フェイルオーバーは手動または自動で行えます。手動は管理者の制御が大きく、複雑な環境やスプリットブレインを避けたい場合に有効です。自動は停止時間を短縮できますが、二つのノードが同時にプライマリだと思い込まないよう慎重な設計が必要です。高可用性では、監視、ヘルスチェック、クォーラム、クラスタ管理が判断を支えます。
可用性はアプリケーションの挙動にも左右されます。レプリカを昇格するだけでは、アプリケーションが再接続できない、DNS更新が遅い、接続プールが故障先を使い続ける、ユーザーが手動設定を求められる、といった問題が残ります。レプリケーションは、アプリケーションルーティング、ロードバランサー、接続文字列、サービス発見、運用手順と一緒に計画する必要があります。
レプリカは保守にも役立ちます。計画アップグレード、パッチ適用、ハードウェア交換、ストレージ移行の際、一部の負荷を別ノードへ移せることがあります。これにより計画停止を減らし、管理者に柔軟性を与えます。強い設計は緊急復旧と日常保守の両方を支えます。
主要データモデルを変えない読み取り拡張
多くのデータベースは書き込みが重いからではなく、読み取りクエリが増えることで過負荷になります。ダッシュボード、レポート、検索ページ、顧客ポータル、監視ツール、API呼び出しが同じデータベースを読むことがあります。すべての読み取りがプライマリに集中すると、通常のトランザクションが遅くなります。レプリケーションは読み取りをレプリカへ分散する方法を提供します。
読み取りレプリカは、レポートや分析によく使われます。長時間のクエリをレプリカ上で実行すれば、プライマリ上の重要なトランザクション処理を妨げたり遅くしたりしません。ビジネス部門が頻繁にレポートを必要とし、本番データベースは応答性を保つ必要がある場合に有効です。
アプリケーション側の読み書き分離も拡張性を高めます。アプリケーションは書き込みをプライマリへ、選択した読み取りをレプリカへ送ります。ただしレプリカは遅延することがあるため注意が必要です。即時整合性が必要なデータはプライマリから読むべき場合があり、少しの遅延を許容できるデータはレプリカに向いています。
この方法は、データモデル全体を作り直さずに読み取り能力を増やせます。すぐに別アーキテクチャへ移行するのではなく、レプリカを追加し、クエリルーティングを最適化し、レポート負荷を分離できます。これはデータベース拡張の実用的な中間段階になることが多いです。
災害復旧と地理的レジリエンス
レプリケーションは災害復旧にもよく使われます。別のデータセンター、クラウドリージョン、物理拠点にあるレプリカは、火災、停電、ネットワーク断、ストレージ障害、拠点災害から守ることができます。プライマリ拠点が使えなくなった場合、遠隔レプリカが復旧経路になります。
地理的レプリケーションでは、距離が遅延を増やすため慎重な計画が必要です。長距離の同期レプリケーションは一部のアプリケーションには遅すぎることがあります。遠隔災害復旧では非同期方式が多いですが、プライマリ拠点がすべての変更をコピーする前に停止するとデータ損失が起こり得ます。
復旧計画ではRTOとRPOを定義します。RTOはサービスをどれほど速く戻すかを表します。RPOは許容できるデータ損失量を表します。厳しいRPOには、より同期的な保護や非常に低い遅延が必要です。柔軟なRPOなら、非同期レプリケーションと定期的な確認で足りる場合があります。
災害復旧にはテストも必要です。一度も昇格されず、アプリケーション互換性も確認されず、現実的な条件で復元されたことのないレプリカは、本番の災害時に信頼できないかもしれません。レプリケーションは技術的基盤を与えますが、訓練がプロセスの有効性を証明します。
データの近接性と地域性能
レプリケーションは、ユーザー、支店、地域アプリケーションの近くにデータを配置できます。異なる場所のユーザーが近くのレプリカから読むと、応答時間が改善することがあります。これは、グローバルアプリケーション、複数リージョンのサービス、小売チェーン、物流ネットワーク、金融プラットフォーム、分散企業システムに有効です。
地域レプリカは中央ネットワークへの負荷も減らします。すべてのクエリを遠距離接続へ送る代わりに、ローカルユーザーやサービスが近くのコピーから読めます。読み取りが多く、データ鮮度の要件が管理可能な場合に特に有効です。
データの近接性はローカルレポートにも役立ちます。地域オフィスは、自分たちの取引、在庫、サービス記録、運用データを、中央本番データベースに常時負荷をかけずに分析できます。ローカルの複製データベースがそのアクセスを提供し、中央システムは主要トランザクションに集中できます。
ただし、地域レプリケーションはデータガバナンスを守らなければなりません。一部のデータは、プライバシー法、内部方針、顧客契約、業界規制で制限されます。別地域や別国へデータをコピーするには、承認、暗号化、アクセス制御、データ最小化が必要になる場合があります。性能向上のためにガバナンスを弱めてはいけません。
バックアップとレプリケーションは同じではない
レプリケーションとバックアップは一緒に語られることが多いですが、解決する問題は異なります。レプリケーションは、可用性、性能、データ配布のために別のデータベースコピーを最新に保ちます。バックアップは、削除、破損、ランサムウェア、誤変更、長期的なデータ損失から復元できる履歴コピーを作ります。
レプリカは誤りも正確にコピーします。ユーザーがプライマリで重要なレコードを削除すると、レプリケーションはレプリカでもすぐに削除する可能性があります。アプリケーションが壊れたデータを書けば、レプリカも同じ状態を受け取ります。この場合、ポイントインタイム復旧、遅延レプリケーション、バックアップがなければ組織は守られません。
バックアップは復元に時間がかかりますが、履歴復旧には安全です。過去の時点へ戻すことができます。レプリケーションはサービス継続には速いですが、履歴ロールバックを保証するものではありません。強いデータベース戦略には通常、レプリケーションとバックアップの両方が必要です。
運用計画ではこの違いを明確にすべきです。速いフェイルオーバーが目的ならレプリケーションが役立ちます。先週のデータを戻すことが目的ならバックアップが必要です。両方が必要なら、両方のプロセスを設計し、定期的にテストする必要があります。
レプリケーションの健全性監視
レプリケーションは継続的に監視する必要があります。数時間遅れているレプリカでもオンラインに見えることがありますが、フェイルオーバーには使えず、レポートにも不正確です。一般的な監視項目には、レプリケーション遅延、レプリカ状態、ログ配送の進行、適用速度、エラー、接続状態、ディスク使用量、トランザクション遅延、同期失敗イベントがあります。
特に重要なのはレプリケーション遅延です。これは、プライマリで発生した変更がレプリカで利用可能になるまでの時間です。小さな遅延はレポート用途では許容できます。大きな遅延はアプリケーションの前提を壊し、フェイルオーバー時のデータ損失リスクを高めます。用途ごとに許容しきい値を決める必要があります。
ストレージと容量も監視すべきです。レプリケーションはログ、一時ファイル、リレーログ、アーカイブログ、ステージングデータを生成します。ディスクが不足するとレプリケーションは停止することがあります。レプリカの性能が不足していると、ピーク時に変更適用が追いつきません。レプリカは軽い予備機ではなく、実際の負荷に合わせて設計すべきです。
運用アラートは実用的でなければなりません。単にレプリケーション失敗を知らせるだけでなく、原因がネットワーク、認証、ログ位置、ディスク容量、スキーマ不一致、権限エラー、競合書き込みのどれかを判断しやすくする必要があります。原因が早く分かれば、データ経路も早く復旧できます。
セキュリティとアクセス制御
レプリケーションは、機密データが存在する場所を増やします。すべてのレプリカはプライマリデータベースと同じ厳しさで保護されなければなりません。レプリカの方が弱ければ、そこが情報漏えいの最も容易な経路になります。セキュリティ計画には、暗号化、アクセス制御、監査ログ、ネットワーク制限、認証情報管理をすべてのノードに含めるべきです。
データセンター、クラウドリージョン、公共ネットワーク、第三者回線をまたぐレプリケーショントラフィックは保護が必要です。転送中の暗号化は盗聴を防ぎます。ノード間認証は、不正なシステムがレプリケーション関係に加わることを防ぎます。ネットワーク分離は無関係なシステムへの露出を減らします。
レプリカの権限は別途見直す必要があります。レポート用レプリカが分析担当者に読み取り専用で提供されるとしても、すべてのテーブルを全員が見てよいわけではありません。機密フィールドにはマスキング、フィルタリング、別のアクセス方針が必要です。場合によっては、レプリカには目的に必要なデータだけを入れるべきです。
管理者アクセスにも統制が必要です。レプリケーション停止、レプリカ昇格、フィルタ変更、認証情報変更ができるユーザーは大きな権限を持ちます。これらの操作は記録し、許可された担当者に限定すべきです。レプリケーションは単なるバックグラウンド処理ではなく、データベースの信頼境界の一部です。
導入時によくある誤り
よくある誤りは、目的を定義せずにレプリケーションを導入することです。目的が可用性なら、フェイルオーバー手順とアプリケーション再接続が必要です。目的がレポートなら、クエリ負荷とデータ鮮度を扱う必要があります。目的が災害復旧なら、遠隔拠点、RTO、RPO、復旧訓練が必要です。曖昧な目的は曖昧な構成を生みます。
もう一つの誤りは、レプリカが常に最新だと思い込むことです。非同期レプリカは遅延します。大量書き込み、不安定なネットワーク、遅いディスク、スキーマ変更、長いトランザクションはレプリケーションを遅らせます。レプリカから読むアプリケーションは、この遅延を前提に設計すべきです。
レプリカの昇格をテストしないチームもあります。レプリカは作るものの、切り替えを練習しません。緊急時に、権限問題、アプリケーション接続問題、欠落ジョブ、不完全な設定、不整合データが見つかります。フェイルオーバーは必要になる前にテストすべきです。
レプリケーションフィルタも混乱を生みます。特定のテーブルやデータベースだけを複製する場合、何が含まれ何が除外されるかをチームが正確に知る必要があります。レポートチームが全データがあると考えても、実際にはスキーマの一部だけかもしれません。明確な文書化が誤解を防ぎます。
最後に、多くの導入では保守を過小評価します。レプリケーションは、アップグレード、スキーマ変更、証明書更新、パスワードローテーション、ストレージ増加、ネットワーク変更、データベースバージョン差に耐える必要があります。一度設定して終わりではありません。所有者が必要です。
レプリケーションが最も価値を発揮する場面
レプリケーションは、可用性、読み取り拡張、災害復旧、データ配布、負荷分離が明確に必要な場合に最も価値を発揮します。データベースが小さく、停止許容度が高く、読み取りが軽く、バックアップ復元で十分な場合は価値が小さくなります。すべてのアーキテクチャ判断と同じく、問題に合わせるべきです。
業務上重要なシステムでは、停止時間を減らし、復旧の選択肢を増やせます。成長中のアプリケーションでは、レポートや読み取りをプライマリから切り離せます。分散組織では地域アクセスを支援できます。データチームには、本番負荷を妨げずに運用データを分析基盤へ届けられます。
強い設計は、多くの場合控えめで明確です。どのノードが書き込みを受けるのか、どのノードが読み取りを処理するのか、遅延をどう監視するのか、フェイルオーバーがどう動くのか、バックアップをどう維持するのか、誰がレプリケーション関係に責任を持つのかを定義します。複雑さは、十分な業務理由がある場合だけ追加すべきです。
レプリケーションは安全を魔法のようにコピーするものではありません。データを複数の場所で利用可能に保つための、規律ある方法です。その利点は、技術設計、アプリケーション挙動、監視、セキュリティ、復旧プロセスを一緒に計画したときに現れます。
FAQ
データベースレプリケーションは主にバックアップ用途ですか?
いいえ。復旧を支援できますが、バックアップの代替ではありません。レプリカは誤削除や破損データもプライマリからコピーしてしまうことがあります。履歴復旧やポイントインタイム復元にはバックアップが必要です。
レプリケーション遅延とは何ですか?
プライマリデータベースで変更がコミットされてから、同じ変更がレプリカに現れるまでの遅れです。非同期レプリケーションでは一般的であり、レプリカを読み取りやフェイルオーバーに使う場合は監視が必要です。
アプリケーションはレプリカに書き込めますか?
プライマリ・レプリカ構成では、レプリカは通常読み取り専用です。マルチプライマリ構成では複数ノードへの書き込みが可能ですが、競合処理と強い運用管理が必要です。
レプリケーションは性能を改善しますか?
読み取り、レポート、分析をプライマリから分離することで性能を改善できる場合があります。ただしすべての負荷を自動的に速くするわけではありません。書き込みの多いシステムでは、インデックス、クエリ最適化、パーティション、ハードウェア改善、構成変更も必要です。
レプリケーションに依存する前に何をテストすべきですか?
初期同期、負荷時の遅延、フェイルオーバー、レプリカ昇格、アプリケーション再接続、バックアップ復旧、監視アラート、セキュリティ権限、ネットワーク断時の挙動をテストすべきです。