クラスターとは、接続されたコンピューター、サーバー、ゲートウェイ、デバイス、アプリケーション、またはネットワークノードが、単一の協調システムとして動作する構成です。単独の機器に依存するのではなく、クラスター設計では負荷を分散し、可用性を高め、フェイルオーバーを支援し、システムの一部が利用できなくなってもサービスを継続しやすくします。
「クラスター」という言葉は、ITインフラ、クラウドコンピューティング、データベース、通信プラットフォーム、電話システム、無線ネットワーク、産業オートメーション、ストレージ、エッジコンピューティングなど多くの分野で使われます。技術的な構成は異なっても、複数の要素が協力してシステム全体をより信頼性高く、拡張しやすく、管理しやすくするという考え方は同じです。

グループ化されたシステムの基本的な考え方
単純な単体システムでは、1台のサーバーまたは1つのデバイスが単独でサービスを処理します。その機器が故障すればサービスは停止する可能性があります。利用者の需要が増えれば過負荷になり、保守が必要な場合には停止を避けにくくなります。
クラスターシステムはこのモデルを変えます。複数のノードがネットワークで接続され、共通のルールの下で管理されます。あるノードが現在の負荷を処理し、別のノードが待機系として備えることもあれば、すべてのノードが同時にトラフィックを処理することもあります。
たとえば企業向け通信プラットフォームでは、複数のサーバーがユーザー登録、通話ルーティング、録音、メディア処理を分担できます。Radio over IP 環境では、複数のゲートウェイが分散した無線チャネル、指令センター、IPネットワークを接続し、拠点間通信を維持します。
グループ化されたノードが連携する仕組み
ノードの参加
ノードはシステム内で役割を持つ参加単位です。物理サーバー、仮想マシン、ゲートウェイ、コントローラー、ストレージ装置、通信端末、ソフトウェアサービスなどが該当します。各ノードは定義された役割を持ち、ネットワークを通じて他のノードと通信します。
同じ機能を実行するノードもあれば、専門的な役割を持つノードもあります。データベースでは1つのノードが書き込みを受け付け、他のノードがデータを複製することがあります。通信システムでは、あるノードがシグナリングを処理し、別のノードがメディア、録音、ゲートウェイ接続を管理します。
ハートビートとヘルスチェック
多くのクラスターでは、ノードが稼働しているか確認するためにハートビート信号を使用します。ハートビートはノード間、または管理コントローラーに定期的に送られる状態メッセージです。ノードが応答しなくなると、システムは故障の可能性があると判断します。
ヘルスチェックでは、CPU使用率、メモリ、ネットワーク状態、アプリケーション応答、サービスプロセス、ディスク容量、ゲートウェイ接続、デバイス登録なども監視できます。これにより、ノードを継続利用するか一時的に外すかを判断できます。
ワークロード分散
一部のクラスターは作業を複数ノードに分散します。ロードバランサー、ルーティングポリシー、共有キュー、分散データベース、アプリケーションレベルの調整などで実現されます。目的は、一部のノードだけが過負荷になり、他のノードが空いている状態を避けることです。
ワークロード分散は性能と拡張性を高めますが、セッション処理、データ同期、ネットワーク容量、監視を適切に設計する必要があります。設計が不十分だと負荷の偏りやサービス不安定につながります。
フェイルオーバー動作
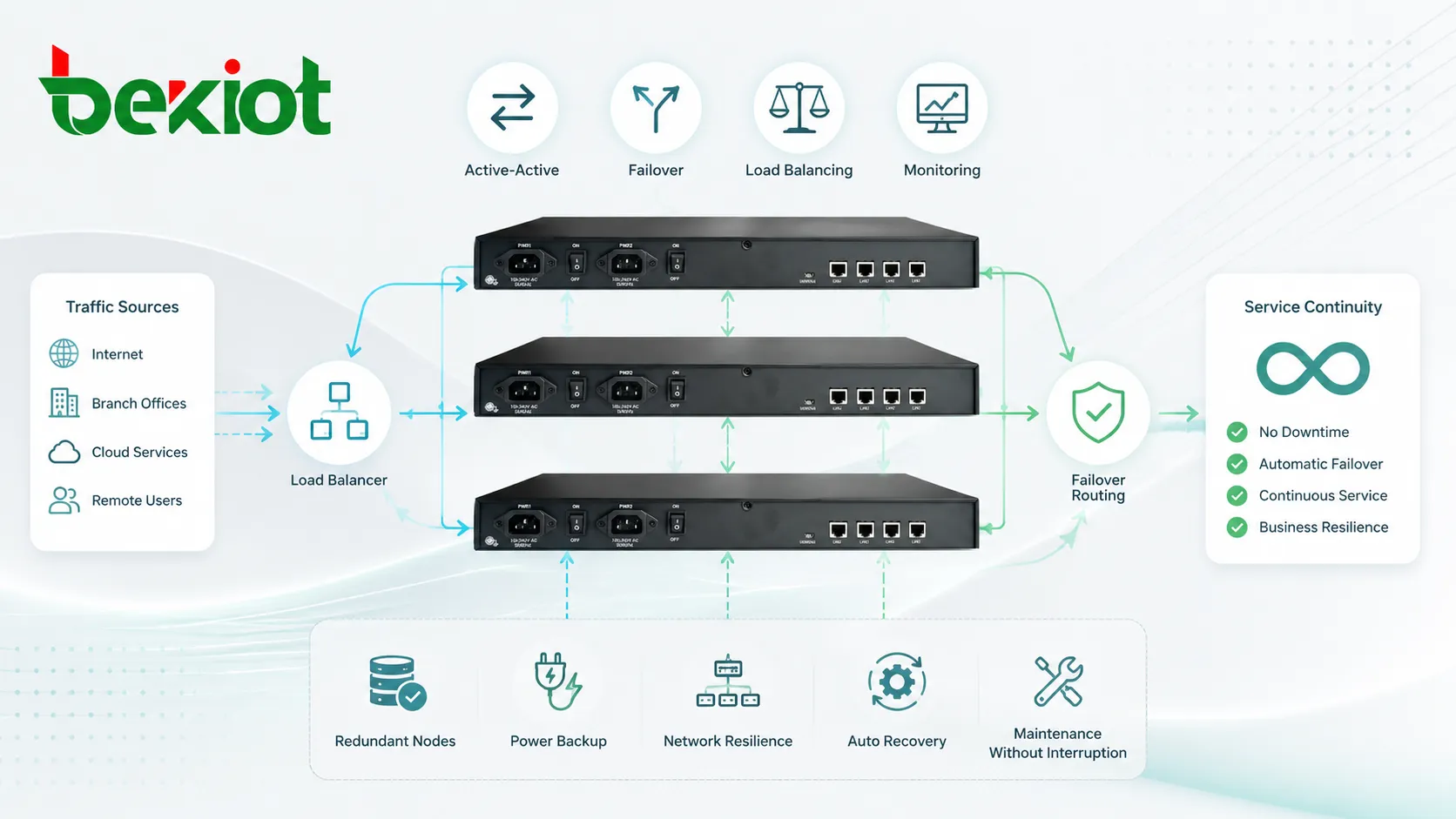
フェイルオーバーとは、あるノードが故障したときに別のノードが役割を引き継ぐことです。アクティブ・スタンバイ構成では、待機ノードはアクティブノードの故障まで待機します。アクティブ・アクティブ構成では、複数ノードがすでにトラフィックを処理し、1台が停止しても残りが追加負荷を吸収します。
フェイルオーバーは慎重にテストする必要があります。待機ノードは、正しい設定、最新データ、ネットワーク接続、ライセンス容量、サービス継続に必要なアプリケーション状態を持っていて初めて有効です。
クラスター設計は単に機器を増やすことではありません。故障、成長、保守を不要な停止なしで処理できるようにノードを協調させることです。
よく見られるアーキテクチャパターン
アクティブ・スタンバイ構成
アクティブ・スタンバイ構成では、1つのノードがサービスを提供し、別のノードがバックアップとして待機します。アクティブノードが故障すると、スタンバイノードが引き継ぎます。一貫性と制御されたフェイルオーバーが、全ノードの同時利用より重要なシステムでよく使われます。
利点はシンプルさです。欠点は、通常運用時にバックアップリソースが十分活用されないことです。ただし重要システムでは、この予備容量が継続性を高めるため受け入れられることが多くあります。
アクティブ・アクティブ構成
アクティブ・アクティブ構成では、複数のノードが同時にサービスを提供します。トラフィックやタスクはそれらの間で分散されます。1つのノードが故障しても残りのノードが利用者にサービスを続けますが、容量は低下する場合があります。
このモデルはリソース利用率と拡張性を高めます。クラウドプラットフォーム、Webアプリケーション、通信システム、分散データベース、多ノードサービス基盤でよく使われます。
ロードバランス型展開
ロードバランス型の展開では、フロントエンドコンポーネントが複数のバックエンドノードにトラフィックを分配します。ロードバランサーは、ラウンドロビン、最少接続、ヘルス状態、送信元アドレス、サービス優先度、地理的位置などのルールを使用できます。
この設計はWebサービス、SIPプラットフォーム、API、アプリケーションサーバー、メディアシステム、企業ポータルで一般的です。ロードバランサー自体も冗長化しなければ、単一障害点になり得ます。
分散エッジ設計
一部のシステムでは、ノードを1つのデータセンターに集約せず、複数の場所に配置します。これは支店通信、産業現場、交通ネットワーク、無線連携、IoTプラットフォーム、公共安全システムで一般的です。
分散エッジ設計は中央サイトへの依存を減らし、現地での応答を改善できます。ただし、信頼できる同期、遠隔監視、セキュリティ制御、明確な保守手順が必要です。
組織がこの設計を採用する理由
高い可用性
可用性はグループ化されたシステムを利用する主な理由の一つです。単体機器が故障するとサービスは停止する可能性がありますが、複数の協調ノードがあれば別のノードがサービスを続けたり、影響を受けた負荷を引き継いだりできます。
これは通信プラットフォーム、緊急サービス、業務アプリケーション、金融システム、医療システム、産業制御、顧客向けサービスにとって重要です。停止は業務上または商業上の影響を生むためです。
成長に対応する拡張性
需要が増えると、組織はより多くの処理能力、通話容量、データベーススループット、ストレージ、ゲートウェイチャネル、サービスエンドポイントを必要とします。クラスター設計では、システム全体を入れ替えるのではなくノード追加で容量を拡張できます。
トラフィックが時間とともに変化する場合、拡張性は特に重要です。システムは小規模に始め、拠点、ユーザー、チャネル、サービス、顧客需要の増加に合わせて拡張できます。
中断の少ない保守
クラスターシステムは保守を容易にします。管理者は1つのノードをサービスから外し、更新、テスト、復帰を行いながら、他のノードでトラフィック処理を継続できます。
ただし計画は不要になりません。互換性、同期、ユーザーセッション、フェイルオーバー動作、ロールバックを考慮する必要があります。それでも単一ノード構成より柔軟性は高くなります。
リソース利用率の改善
アクティブ・アクティブまたはロードバランス型システムでは、複数ノードが作業を分担できます。容量が1台の機器に限定されないため、リソース利用率が高まります。
たとえば複数のアプリケーションサーバーは1台より多くのユーザーを処理できます。複数のメディアゲートウェイはより多くの音声チャネルを支え、複数のストレージノードは容量と回復力を高めます。
サービス耐障害性の向上
レジリエンスとは、負荷、部分故障、保守、トラフィック変化の下でもシステムが動作を続けられる能力です。クラスター設計は責任を分散し、単一コンポーネントへの依存を減らすことでそれを支えます。
ミッションクリティカルな環境では、バックアップ電源、ネットワーク冗長化、地理的分離、監視、セキュリティ強化、検証済み復旧手順も含めて考える必要があります。
重要な技術要素
共有設定
ノードが予測可能に動作するには、一貫した設定が必要です。ネットワーク設定、ユーザーデータ、ルーティングルール、セキュリティ証明書、サービスパラメータ、ライセンス情報、アプリケーションポリシーなどが含まれます。
設定がずれると、フェイルオーバーや負荷共有が不安定になります。集中設定管理や自動展開は、このリスクを減らします。
データ同期
一部のシステムではノード間のデータ同期が必要です。ユーザーセッション、通話状態、データベース記録、キュー状態、デバイス登録、ボイスメールデータ、アクセス権、アラーム記録などが対象になります。
同期設計は重要です。データが最新でなければ、バックアップノードが引き継いでも期待されるサービス状態を提供できません。同期が重すぎると性能負荷になります。
クォーラムとスプリットブレイン保護
一部のクラスターでは、どのノードが意思決定できるかを決めるためにクォーラムを使用します。これはネットワーク分断後に2つの部分が同時に自分をアクティブだと考えるスプリットブレインを防ぐのに役立ちます。
スプリットブレインは、データの矛盾、重複したサービス制御、不安定なフェイルオーバーを引き起こすため危険です。適切なクォーラム設計、フェンシング、ネットワーク冗長化でリスクを下げられます。
監視とアラート
監視は不可欠です。クラスターでは部分故障が隠れることがあります。サービスはオンラインに見えても、ノード、リンク、ディスク、ゲートウェイ、プロセスの一部が故障している可能性があります。
管理者はノードの健全性、トラフィック分布、フェイルオーバーイベント、同期状態、リソース使用率、エラーログ、サービスレベル指標を監視すべきです。アラートは故障の有無だけでなく、注意が必要な部品を示す必要があります。
セキュリティ制御
グループ化されたシステムは、単体システムより内部通信が多くなります。ノード間では状態、設定、データ、認証情報、制御メッセージが交換されるため、認証、暗号化、セグメント化、アクセス制御で保護する必要があります。
管理アクセスも制御すべきです。1つのノードが侵害されても、攻撃者が環境全体を自動的に支配できないようにする必要があります。
通信とゲートウェイのシナリオ
通信ネットワークでは、クラスターの考え方は PBX プラットフォーム、SIP サーバー、指令システム、ゲートウェイ、Radio over IP ネットワーク、録音プラットフォーム、コンタクトセンター、緊急通信システムに多く見られます。通信障害は日常運用、安全対応、顧客サービスに影響するため、これらのサービスには継続性が必要です。
無線と指令の統合では、クラスター化されたゲートウェイ設計により、複数の無線チャネル、IPネットワーク、制御センターを接続できます。ゲートウェイグループは、チャネル拡張、フェイルオーバー、リモートアクセス、拠点間の集中管理を提供できます。
たとえば Becke Telcom の BK-ROIP シリーズ クラスターゲートウェイは、無線システムを IP 指令プラットフォーム、複数拠点の指揮センター、企業通信ネットワークへ接続するプロジェクトで利用できます。このような場面では、ゲートウェイ層が無線音声、IP伝送、業務指令フローを橋渡しし、ソリューションを拡張しやすく管理しやすく保ちます。
業界別の用途
企業 IT システム
企業は業務アプリケーション、データベース、ファイルサービス、メール、ID基盤、社内ポータルにクラスターサーバーを使用します。これらのシステムは、ハードウェア故障、ソフトウェア更新、トラフィックピーク時にも利用可能である必要があります。
企業 IT における主な目的は、稼働時間、予測可能な性能、容易な保守、事業継続です。設計は各アプリケーションの重要度に合わせる必要があります。
クラウドとデータセンター
クラウドプラットフォームはグループ化されたリソースに大きく依存します。計算ノード、ストレージノード、ネットワークコントローラー、アプリケーションサービスが分散され、ワークロードの拡張と障害復旧を可能にします。
データセンターでは、この設計が高可用性、リソースプール、仮想化、コンテナオーケストレーション、自動ワークロード移行を支えます。
電話システムとユニファイドコミュニケーション
音声プラットフォームでは、登録、通話ルーティング、メディアサービス、ボイスメール、録音、コンタクトセンターキュー、SIPトランク制御にグループ化されたサーバーを利用できます。これにより、1台のサーバー故障が全ユーザーの通信を止めるリスクを減らせます。
複数拠点の企業では、分散通信ノードがローカルの生存性も高めます。中央サイトとの接続が一時的に利用できない場合でも、支店内の通信を継続できる場合があります。
産業およびエネルギー施設
工場、公益事業、石油・ガス施設、鉱山、港湾、発電施設では、監視、指令、アラーム処理、無線統合、アクセス制御、制御室通信にグループ化されたシステムを使うことがあります。
これらの環境では、稼働時間とレジリエンスが特に重要です。冗長電源、ネットワーク保護、環境条件、保守手順と合わせて計画する必要があります。
公共安全と緊急対応
緊急対応組織は、グループ化された通信サーバー、指令プラットフォーム、無線ゲートウェイ、録音システム、通知ツールを使用できます。需要が増加したりインフラの一部が故障したりしても通信を維持することが目的です。
これらのシステムは、フェイルオーバー、バックアップ電源、高通話量、複数機関連携、ネットワーク障害など、現実的な条件でテストする必要があります。

適切な構成を計画する
まずサービス目標を定義する
クラスター設計を選ぶ前に、組織はサービス目標を定義する必要があります。目標は高可用性、負荷分担、地理的冗長性、保守の柔軟性、チャネル拡張、災害復旧、複数拠点統合などです。
目標ごとに適したアーキテクチャは異なります。フェイルオーバーを主目的とするシステムは、性能拡張を目的とするシステムと同じとは限りません。
故障点を特定する
他の部品が冗長化されていなければ、クラスターシステムも失敗する可能性があります。電源、ネットワークスイッチ、ルーター、ストレージ、ファイアウォール、ロードバランサー、ライセンス、データベース、管理基盤は単一障害点になり得ます。
計画ではノードだけを見るのではなく、サービス経路全体を確認する必要があります。
アプリケーション互換性を確認する
すべてのアプリケーションやデバイスがクラスター向けに設計されているわけではありません。特別なライセンス、データベース対応、同期ロジック、共有ストレージ、ベンダー固有アーキテクチャが必要な場合があります。
展開前に互換性を確認すべきです。紙の上で良く見える設計でも、アプリケーションがアクティブ・アクティブ運用や状態同期に対応できなければ失敗する可能性があります。
復旧動作をテストする
フェイルオーバーは本番利用前にテストすべきです。テストには、ノード故障、ネットワーク中断、サービス再起動、データベース遅延、停電、保守モード、通常運用への復帰を含めます。
復旧テストは、遅いフェイルオーバー、不完全なデータ同期、誤ったルーティング、ユーザーセッション喪失などの隠れた問題を明らかにします。
よくある課題
一般的な課題は複雑さです。ノード、リンク、同期ルールが増えるほど、設定と監視の対象も増えます。管理が不十分なクラスターは、単純な単体システムよりトラブルシューティングが難しくなることがあります。
もう一つの課題は過信です。ノードを増やせば自動的に高可用性になると考える組織があります。実際には、冗長化、監視、フェイルオーバーロジック、検証済み復旧、熟練した保守を含む全体設計が必要です。
コストも考慮すべき点です。追加ノード、ライセンス、ストレージ、スイッチ、ゲートウェイ、ソフトウェアモジュール、サポートサービスはプロジェクト費用を増やします。投資は停止や容量不足の事業リスクに見合うべきです。
クラスターシステムは、ノードが多ければ自動的に信頼性が高まるという考えではなく、実際のサービス要件に基づいて設計すべきです。
保守と運用
定期保守には、ノードのヘルスチェック、設定確認、バックアップ検証、フェイルオーバーテスト、ログ分析、性能監視、セキュリティ更新を含める必要があります。テストされていないクラスターは、最も必要なときに予期せず失敗することがあります。
管理者は設定ドリフトにも注意すべきです。1つのノードを手動更新して他のノードが更新されない場合、動作が不一致になります。自動設定ツールと文書化された変更管理はこのリスクを下げます。
容量は時間とともに見直す必要があります。1つのノードが故障した場合、残りのノードには重要な負荷を処理できる十分な容量が必要です。そうでなければ、サービスはオンラインでも性能が許容できない可能性があります。
適切なソリューションの選び方
適切なソリューションは、ワークロードの種類、サービス重要度、ユーザー規模、拠点分布、復旧要件、予算によって異なります。小規模オフィスのアプリケーションなら基本的なバックアップと復元で足りることもありますが、通信事業者レベルのプラットフォームでは複数拠点のアクティブ・アクティブ冗長化が必要な場合があります。
通信プロジェクトでは、通話容量、チャネル容量、SIP互換性、メディア処理、無線連携、ゲートウェイ冗長化、集中管理、ログ、フェイルオーバー動作を考慮すべきです。無線、IP指令、企業通信を接続する場合、ゲートウェイの拡張性と拠点単位のレジリエンスが特に重要になります。
組織は長期保守も考える必要があります。ソリューションは理解しやすく、文書化され、監視でき、日常運用を担当するチームが支援できるものであるべきです。
FAQ
小規模企業でもクラスターシステムを使えますか?
はい。小規模企業は複雑な多ノード基盤を必要としない場合がありますが、冗長ファイアウォール、バックアップサーバー、複製ストレージ、クラウド管理サービスなどの簡易な高可用性設計を利用できます。
クラスターには常に同一ハードウェアが必要ですか?
必ずしもそうではありません。同一ハードウェアや同一ソフトウェアバージョンが必要なシステムもあれば、混在ノードを許容するシステムもあります。ただし容量やバージョンの差は、性能、フェイルオーバー、サポート性に影響します。
冗長化とクラスタリングの違いは何ですか?
冗長化はバックアップ部品を持つことです。クラスタリングは、複数の部品が共通ロジックの下で協調する設計です。クラスターは通常冗長性を含みますが、冗長性だけで必ずクラスターとは限りません。
なぜフェイルオーバーが想定より遅いことがありますか?
ヘルスチェックタイマー、データベース同期、サービス起動時間、ルーティング収束、DNSキャッシュ、セッション復旧、手動承認などにより遅れることがあります。これらは本番前にテストすべきです。
展開後に何を文書化すべきですか?
ノードの役割、IPアドレス、サービス依存関係、フェイルオーバールール、管理アカウント、監視しきい値、バックアップ手順、保守時間帯、復旧手順、連絡責任者を文書化する必要があります。