

障害発生時にもサービスを継続する
フェイルオーバーとは、主要コンポーネントに障害が発生したとき、処理を自動または手動でバックアップコンポーネントへ切り替える信頼性の仕組みです。ハードウェア、ソフトウェア、リンク、サービスが停止した場合でも、アプリケーション、ネットワーク、サーバー、データベース、通信システム、クラウドサービス、産業プラットフォームを利用可能に保つために使われます。
簡単に言えば、フェイルオーバーは「主システムが止まったら、何が引き継ぐのか」という問いに答えるものです。適切に設計された構成は、停止時間を短縮し、サービス継続性を守り、障害、過負荷、保守作業、予期しない停止からの復旧を早めます。
フェイルオーバーはすべての障害を防ぐものではありません。価値は、障害が起きたときに準備済みの復旧経路を持たせる点にあります。
基本的な意味とシステム上の役割
フェイルオーバーは高可用性設計でよく使われます。通常運用はプライマリ資源が担当し、プライマリが利用不能になった場合に備えて、1つ以上のスタンバイ資源が待機します。バックアップ資源には、別サーバー、ルーター、データベースノード、ネットワークリンク、データセンター、クラウドリージョン、ストレージ、アプリケーションインスタンスなどがあります。
目的はサービス中断を減らすことです。故障した部品の修理を待つのではなく、トラフィック、ワークロード、セッション、リクエストを別の利用可能な資源へ転送します。
プライマリ資源とスタンバイ資源
プライマリ資源は通常サービスを提供するアクティブなコンポーネントです。スタンバイ資源は、プライマリに障害が発生したときに引き継げるよう準備されます。あるシステムでは受動的に待機し、別のシステムでは複数資源が同時にトラフィックを処理します。
例えば、Webサイトを2台のアプリケーションサーバーで動かすことがあります。1台目が故障すると、トラフィックは2台目へ送られます。ルーターは主回線が切れたときにバックアップWANを使えます。データベースは元の主ノードが故障したとき、レプリカを新しい主ノードへ昇格できます。
障害検出
フェイルオーバーは障害検出に依存します。システムは、プライマリコンポーネントが正常でないことを把握しなければなりません。検出には、ハートビート、ヘルスチェック、リンク監視、サービスプローブ、データベース複製状態、アプリケーション応答確認、ネットワーク到達性テストなどが使われます。
良い検出は、停止時間を短くするために十分速く、同時に短い遅延や一時的なパケットロスで不要な切り替えを起こさない程度に安定している必要があります。このバランスは実際のネットワークやアプリケーション設計で重要です。
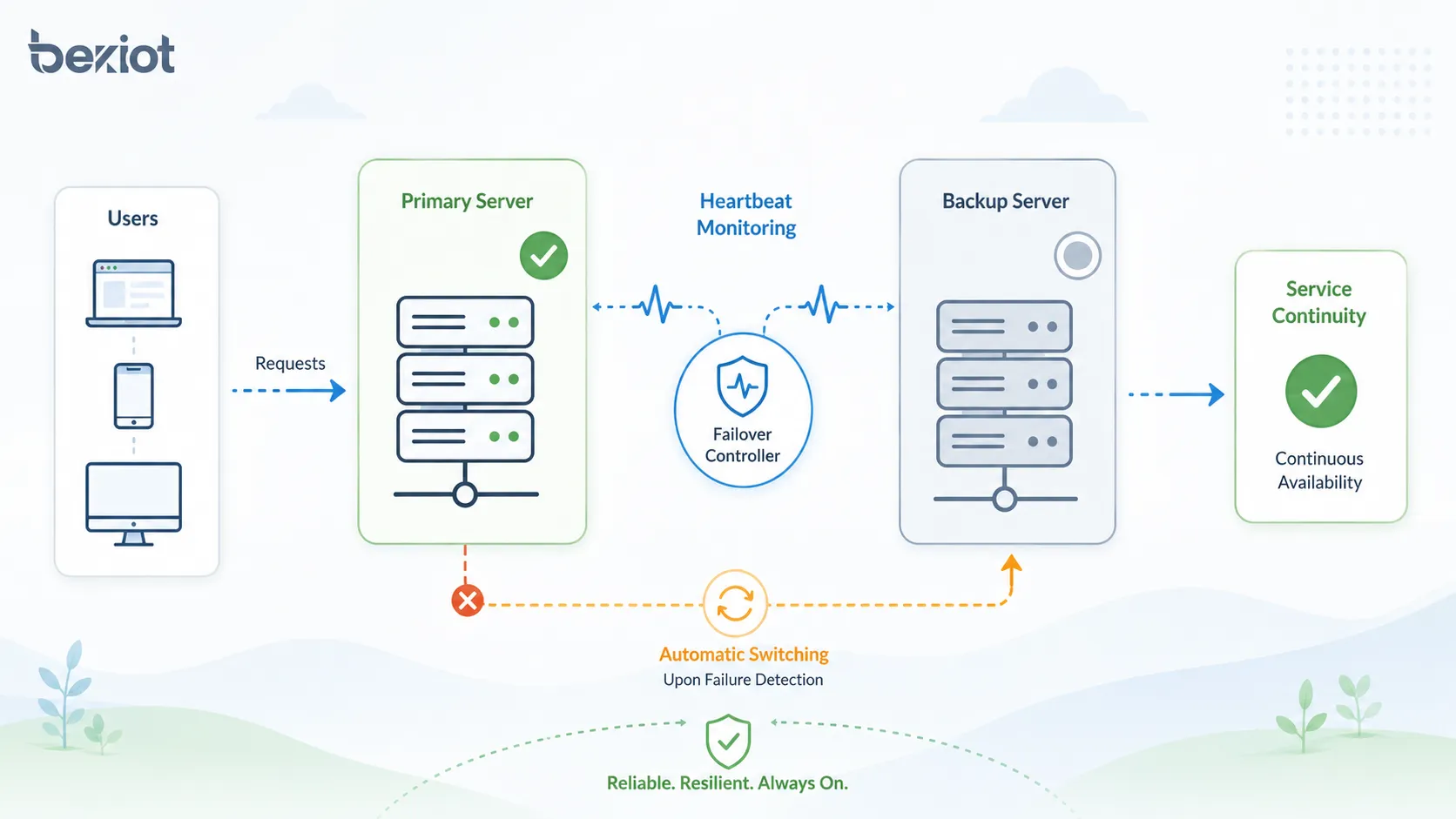
フェイルオーバー処理の流れ
フェイルオーバー処理は通常、監視、障害検出、判断、サービス切り替え、トラフィック転送、復旧確認、イベント記録で構成されます。詳細はシステムの種類によって異なりますが、中心となる考え方は共通しています。
監視機構が主システムの停止や異常を検出すると、フェイルオーバー制御がバックアップ経路を有効にします。ユーザーには短い中断が見える場合がありますが、サービスはバックアップコンポーネント経由で継続する必要があります。
監視とヘルスチェック
ヘルスチェックはサービスが正しく動いているかを確認します。基本的なチェックではサーバーがpingに応答するかだけを見ます。高度なチェックでは、アプリケーションが要求を処理し、データベースへ接続し、有効な応答を返すかを確認します。
アプリケーションレベルのチェックは、単純なネットワークチェックより信頼できます。サーバーがpingに応答していても、アプリケーションが停止、過負荷、または必要なバックエンドサービスへ接続できないことがあります。
バックアップ資源への切り替え
障害が確認されると、システムは処理をバックアップ資源へ移します。ルーティングテーブルの変更、DNSレコード更新、仮想IP移動、データベースレプリカ昇格、スタンバイサーバー起動、ロードバランサーによる転送などが含まれます。
切り替え方法は業務要件に合わせる必要があります。数分の停止を許容できるシステムもあれば、重要システムではユーザー影響を最小にしたほぼ即時の切り替えが必要です。
切り替え後のサービス確認
フェイルオーバー後はバックアップサービスを確認する必要があります。ユーザーが接続できること、トランザクションが継続できること、データが利用可能であること、依存サービスが正常であることを確認します。
トラフィックをバックアップへ送るだけでは正常運用は保証されません。バックアップは同期され、正しく設定され、ワークロードを処理できる容量を持つ必要があります。
主なフェイルオーバーの種類
フェイルオーバーは、システムの重要度、予算、性能要件、復旧目標に応じて設計されます。代表的な方式には、アクティブ・パッシブ、アクティブ・アクティブ、手動、自動、ローカル、地理的フェイルオーバーがあります。
アクティブ・パッシブ方式
アクティブ・パッシブ方式では、1つのシステムが本番トラフィックを処理し、もう1つが待機します。アクティブ側が故障すると、パッシブ側がアクティブになりサービスを引き継ぎます。
この方式は比較的単純で、サーバー、ファイアウォール、データベース、PBX、ストレージコントローラー、ネットワークゲートウェイで広く使われます。利点は役割分担が明確なこと、制限は通常時に待機資源が十分利用されないことです。
アクティブ・アクティブ方式
アクティブ・アクティブ方式では、2つ以上のシステムが同時にトラフィックを処理します。1つが故障しても残りがサービスを続け、追加負荷を吸収します。
この方式は資源利用率と拡張性を高めますが、慎重な設計が必要です。負荷分散、データ同期、セッション処理、競合制御、容量計画がより複雑になります。
手動と自動のフェイルオーバー
手動フェイルオーバーは、オペレーターや管理者が切り替えを実行します。人による制御が可能で、保守、計画移行、慎重なシステム変更に適しています。
自動フェイルオーバーはシステムルールで実行されます。高速で高可用性環境に適していますが、誤切り替え、スプリットブレイン、ノード間の繰り返し切り替えを避けるため、慎重な設定が必要です。
ローカルと地理的フェイルオーバー
ローカルフェイルオーバーは同じサイト、ラック、データセンター、ネットワークゾーン内で発生します。サーバー、リンク、電源モジュール、機器の局所的な故障を保護します。
地理的フェイルオーバーは、別のデータセンター、クラウドリージョン、遠隔拠点へサービスを切り替えます。データセンター停止、地域ネットワーク障害、停電、火災、洪水、大規模インフラ事故への備えになります。
信頼できる設計の重要機能
良いフェイルオーバーは、速く切り替わるだけでは不十分です。安全で、一貫性があり、予測可能に切り替わる必要があります。重要な機能には、監視、冗長化、同期、トラフィック制御、ログ、復旧計画があります。
冗長コンポーネント
冗長化とは、障害が起きる前にバックアップコンポーネントを用意することです。サーバー、電源、ネットワークリンク、ルーター、スイッチ、ストレージ経路、データベース、アプリケーションインスタンス、クラウドリージョンなどが含まれます。
冗長化には実効性が必要です。バックアップサーバーが同じ故障電源や単一スイッチに接続されている場合、本当の耐障害性は得られません。隠れた単一障害点を避ける必要があります。
ハートビートと状態監視
ハートビート信号は、主ノードが生きているかを確認します。スタンバイノードが一定時間ハートビートを受信しなくなると、主ノードが故障したと判断することがあります。
ハートビート設計では、ネットワーク遅延、パケットロス、管理リンクの信頼性を考慮します。設定が悪いと、2つのノードが同時に自分をアクティブだと判断するスプリットブレインが起きます。
データ同期
多くのフェイルオーバーシステムでは、主ノードとバックアップノードの間でデータ同期が必要です。データベース複製、ファイル同期、ストレージミラーリング、設定バックアップ、状態共有などが含まれます。
同期は復旧品質に影響します。バックアップのデータが古いと、サービスは復旧しても最近の取引を失う可能性があります。同期が遅すぎると、復旧時点目標を満たせません。
自動トラフィック転送
トラフィック転送により、ユーザーやシステムはフェイルオーバー後にバックアップサービスへ到達できます。ロードバランサー、仮想IP、ルーティングプロトコル、DNSフェイルオーバー、SD-WANポリシー、アプリケーションゲートウェイなどを使います。
転送方法は期待する復旧時間に合わせる必要があります。DNS方式は簡単ですが、キャッシュにより遅くなる場合があります。ローカル高可用性環境では、ロードバランサーや仮想IP方式のほうが速いことがあります。
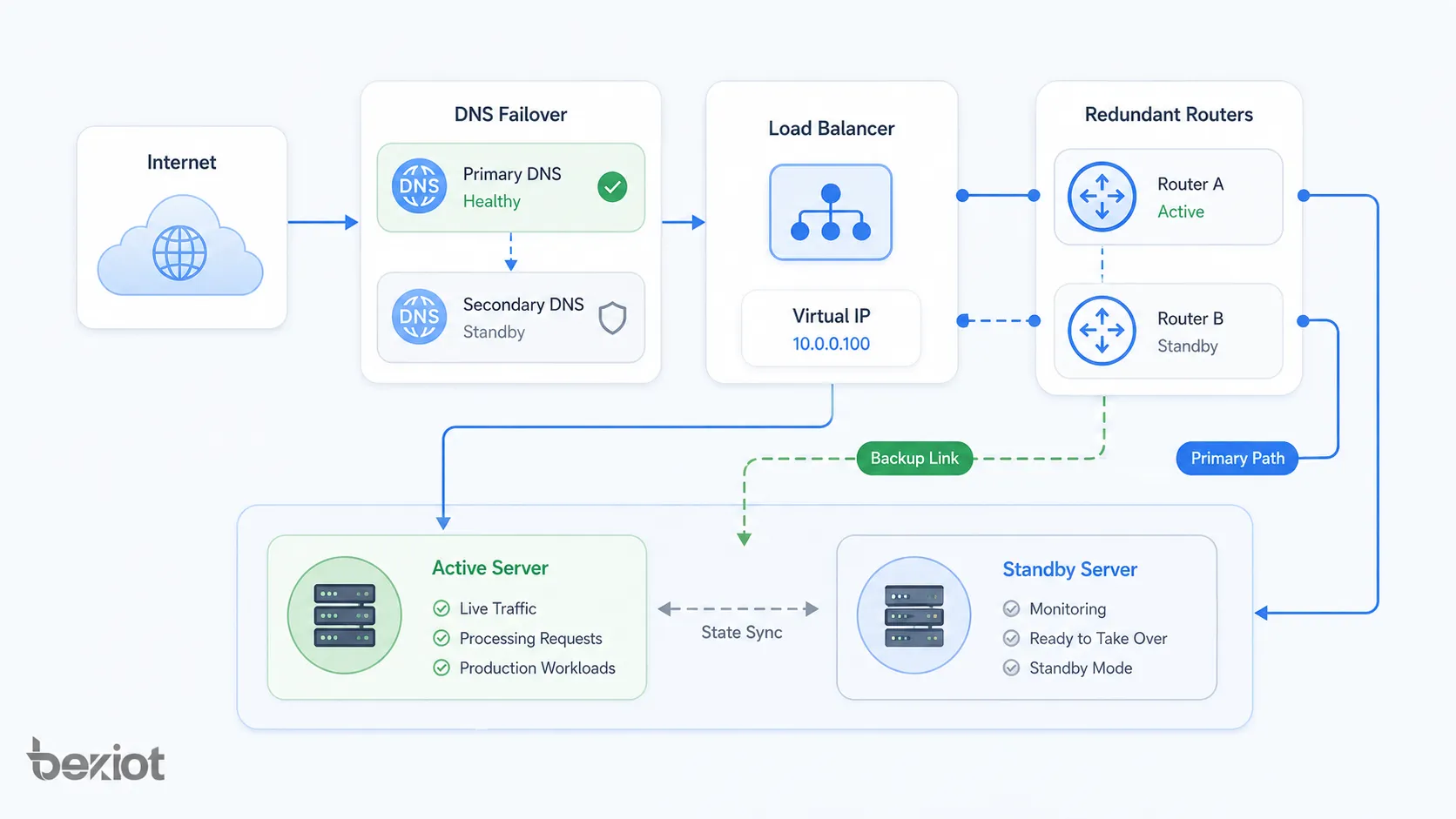
ネットワークアーキテクチャのパターン
フェイルオーバー構成は、ネットワークやシステムスタックのさまざまな層に適用できます。物理リンク、ルーティング経路、サーバークラスタ、データベース、クラウドリージョン、アプリケーションサービスを保護できます。
サーバーレベルのフェイルオーバー
サーバーレベルのフェイルオーバーは、2台以上のサーバーで同じサービスを提供します。1台が故障すると別のサーバーが引き継ぎます。アプリケーションサーバー、Webサーバー、ファイルサーバー、通信サーバー、管理プラットフォームで一般的です。
この方式では、クラスタリングソフトウェア、仮想化基盤、ロードバランサー、コンテナオーケストレーション、高可用性サービスを利用できます。サーバー間の設定一貫性が重要です。
ネットワークリンクのフェイルオーバー
ネットワークリンクのフェイルオーバーは、主接続が故障したときにバックアップ経路を使います。例として、デュアルWAN、バックアップ光回線、LTEまたは5Gバックアップ、冗長ISP接続、SD-WANリンク切り替えがあります。
これは支店、遠隔拠点、小売チェーン、産業施設、クラウド接続システムで重要です。主リンクが停止しても、バックアップリンクにより通信を継続できます。ただし帯域幅や遅延は変わる場合があります。
ルーターとファイアウォールのフェイルオーバー
ルーターやファイアウォールは、高可用性ペアをサポートすることが多くあります。片方がアクティブで片方が待機する構成、または両方で負荷を分担する構成があります。仮想ゲートウェイアドレスを使うと、クライアントはどの物理機器がアクティブかを意識する必要がありません。
ファイアウォールのフェイルオーバーでは、可能な限りセッション状態を同期する必要があります。セッション同期がない場合、新しい接続は続いても、既存接続は切り替え時に切断されることがあります。
データベースフェイルオーバー
データベースフェイルオーバーは、障害が発生した主データベースからレプリカまたはスタンバイデータベースへ切り替えてデータサービスを保護します。企業アプリケーション、EC、金融システム、クラウドサービス、重要な運用プラットフォームで使われます。
この設計では、複製遅延、トランザクション整合性、書き込み競合、アプリケーション再接続を慎重に扱う必要があります。設計が悪いと、データ損失やアプリケーションエラーが発生します。
クラウドとマルチリージョンのフェイルオーバー
クラウドフェイルオーバーは、ゾーン、リージョン、クラウドプロバイダー間でサービスを切り替えます。局所的なインフラ障害から保護し、災害復旧戦略を支えます。
マルチリージョン構成では、グローバルトラフィック管理、複製データベース、オブジェクトストレージ同期、IDサービスの可用性、検証済み復旧手順が必要になる場合があります。設計はRTOとRPOに合わせる必要があります。
フェイルオーバー指標と計画目標
フェイルオーバー計画では、可用性と復旧の指標がよく使われます。これらの指標は、必要な冗長化レベルと、許容できる停止時間またはデータ損失を判断する助けになります。
| 指標 | 意味 | 重要な理由 |
|---|---|---|
| RTO | 復旧時間目標 | 障害後にサービスを復旧するまでの最大許容時間 |
| RPO | 復旧時点目標 | 時間で測定される最大許容データ損失量 |
| MTTR | 平均修復時間 | 故障コンポーネントを復旧する平均時間 |
| MTBF | 平均故障間隔 | 故障と故障の間の平均稼働時間 |
| 可用性 | サービスが稼働している時間の割合 | サービス全体の稼働率を示す |
復旧時間目標
復旧時間目標は、障害後にどれだけ速くサービスを復旧しなければならないかを定義します。重要度の低い社内レポートツールは数時間の停止を許容できますが、決済システム、緊急プラットフォーム、生産制御システムでは数秒または数分以内の復旧が必要です。
低いRTOには、通常、自動化、冗長化、監視、インフラへの追加投資が必要です。すべてのシステムを同じ保護レベルにするのではなく、業務影響に合わせて設計します。
復旧時点目標
復旧時点目標は、どれだけのデータ損失を許容できるかを定義します。数秒分のデータ損失しか許されない場合は、ほぼリアルタイムの複製が必要です。数時間を許容できる場合は、定期バックアップで十分なことがあります。
RPOは、データベース、ファイルシステム、取引プラットフォーム、顧客記録、運用ログで特に重要です。データ計画のないフェイルオーバーは、サービスを戻しても受け入れられない業務損失を生む可能性があります。
ビジネスと運用への利点
フェイルオーバーは、停止時間が売上、安全性、生産性、顧客信頼、運用継続性に影響するため価値があります。適切な戦略は、予期しない故障や計画保守中にもサービスを維持します。
より高いサービス可用性
主な利点は可用性の向上です。プライマリコンポーネントが故障しても、バックアップコンポーネントがサービスを続けます。これにより停止時間を減らし、ユーザーの作業継続を助けます。
高可用性は、オンラインサービス、通信システム、医療プラットフォーム、交通ネットワーク、産業自動化、金融システム、公開アプリケーションに重要です。
運用リスクの低減
フェイルオーバーは、1つのコンポーネント障害がシステム全体を止めるリスクを下げます。単一のインターネット回線、サーバー、データベース、ゲートウェイなど、単一障害点を持つシステムで特に重要です。
バックアップ経路と自動復旧ロジックを追加することで、ハードウェア故障、ネットワーク停止、ソフトウェアクラッシュ、保守中断の影響を減らせます。
保守の柔軟性向上
フェイルオーバーは計画保守にも役立ちます。管理者はサービスを別ノードへ移し、主システムを更新し、変更をテストし、作業完了後に戻すことができます。
これにより長い保守時間の必要性が減ります。バックアップ資源でサービスを継続できるため、アップグレードも安全になります。
ユーザー信頼の向上
ユーザーはフェイルオーバー処理を直接見ないかもしれませんが、サービスが利用可能であり続けることは認識します。信頼できるシステムは顧客信頼、従業員生産性、デジタル基盤への信頼を高めます。
重要な通信、産業、業務プラットフォームにおいて、可用性は単なる技術指標ではありません。サービス体験の一部です。
さまざまなシステムでの用途
フェイルオーバーは継続性が重要な場所で使われます。具体的な設計はシステムの種類によって異なりますが、目的は同じです。何かが故障したときにサービス中断を避けることです。
企業ネットワーク
企業ネットワークでは、インターネットリンク、ファイアウォール、ルーター、スイッチ、VPNトンネル、無線コントローラー、支店接続にフェイルオーバーを使います。1つの経路が故障すると、トラフィックは別経路へ移動します。
複数拠点の組織では、遠隔オフィスがクラウドサービス、データセンター、通信システム、業務アプリケーションへ接続し続けるために役立ちます。
データセンターとクラウドプラットフォーム
データセンターでは、サーバー、ストレージ、データベース、仮想化クラスタ、電源、冷却、ネットワークファブリックにフェイルオーバーを使います。クラウドでは可用性ゾーン、リージョン切り替え、ロードバランサー、自動スケーリング、マネージドデータベースレプリカが使われます。
これらの設計は、正しく計画されていれば、ハードウェア、ホスト、ラック、あるいはリージョンサービスの障害からアプリケーションを守ります。
VoIPと通信システム
VoIPおよびSIPシステムでは、SIPサーバー、PBX、ゲートウェイ、SBC、SIPトランク、DNS SRVレコード、メディアサーバー、ネットワークリンクにフェイルオーバーを使えます。サーバーやトランクが故障すると、通話はバックアップ経路へルーティングされます。
音声サービスの停止は、顧客対応、社内連携、緊急通話、サービス運用に影響するため、企業通信にとって重要です。
産業および運用技術
産業環境では、SCADAサーバー、制御ネットワーク、監視プラットフォーム、HMIステーション、ヒストリアン、産業ゲートウェイ、通信リンクにフェイルオーバーを使えます。目的は、生産、監視、安全関連運用を利用可能に保つことです。
産業向け設計では、決定性通信、機器互換性、環境条件、安全な運用手順を考慮する必要があります。自動切り替えが危険な機械動作を生んではいけません。
Webアプリケーションとオンラインサービス
Webアプリケーションは、ロードバランサー、複製アプリケーションサーバー、データベースレプリカ、CDN、DNSフェイルオーバー、マルチリージョン展開でフェイルオーバーを実現します。これによりサーバーやネットワーク障害時もWebサイトやAPIを利用可能に保てます。
EC、銀行、SaaS、ストリーミング、顧客ポータルでは、予期しない停止時に売上とユーザー体験を守ります。
一般的な課題とリスク
フェイルオーバーはレジリエンスを高めますが、設計が悪いと新しい問題を生みます。バックアップシステムは、テスト、更新、同期、適切な容量設計が必要です。そうでなければ、最も必要なときにフェイルオーバーが失敗する可能性があります。
誤フェイルオーバー
誤フェイルオーバーとは、主サービスが本当に故障していないのに、システムがバックアップへ切り替わることです。一時的なパケットロス、応答遅延、監視過負荷、過度に厳しいしきい値が原因になります。
誤フェイルオーバーは、ユーザーに不要な中断を与えます。ヘルスチェックは、切り替え前に本当のサービス障害を確認するよう設計する必要があります。
スプリットブレイン状態
スプリットブレインは、2つのノードがどちらも自分をアクティブなプライマリだと考える状態です。ハートビート通信だけが失われ、両方のシステムがまだ動いている場合に起こります。
データベース、ストレージ、クラスタシステムでは、スプリットブレインはデータ破損や競合書き込みを引き起こすため危険です。クォーラム、フェンシング、適切なクラスタ設計がリスクを下げます。
バックアップ容量の問題
バックアップ資源には、フェイルオーバー後のワークロードを処理する十分な容量が必要です。バックアップが小さすぎると、サービスは技術的にはオンラインでも性能が大きく低下します。
容量計画では、ピーク負荷、成長、縮退運転、複数障害が同時に起きる可能性を考慮します。
未検証の復旧計画
一度もテストされていないフェイルオーバー設計は信頼できません。設定のずれ、期限切れ証明書、古いバックアップ、ファイアウォール変更、DNSキャッシュ、ライセンス不足、古いソフトウェアが復旧を妨げることがあります。
定期的なフェイルオーバー訓練が必要です。可能であれば、計画的な切り替えと予期しない障害シナリオの両方をテストします。
信頼できる導入のベストプラクティス
フェイルオーバーは、高可用性と災害復旧の広い戦略の一部として設計する必要があります。アーキテクチャ計画、監視、文書化、テスト、継続的改善を含めるべきです。
重要サービスを先に特定する
すべてのシステムに同じフェイルオーバーレベルが必要なわけではありません。どのサービスが重要か、停止が運用へどう影響するか、どの復旧目標が必要かを特定します。
これにより投資の優先順位を決めやすくなります。重要システムでは自動フェイルオーバーと地理的冗長化が必要な場合があり、重要度の低いシステムではバックアップと手動復旧で足りる場合があります。
隠れた単一障害点を取り除く
フェイルオーバーは隠れた依存関係で弱くなります。バックアップサーバーが主サーバーと同じストレージ、電源、ネットワークスイッチ、DNSサービス、認証システムに依存していることがあります。
アーキテクチャレビューでこれらの依存関係を見つけます。本当のレジリエンスには、見えるアプリケーション層だけでなく、サービス経路全体の冗長化が必要です。
設定を同期して保つ
主システムとバックアップシステムは一貫した設定を使う必要があります。ソフトウェアバージョン、ファイアウォールルール、証明書、ルーティングポリシー、ユーザーデータ、アプリケーション設定の差異は、フェイルオーバー失敗の原因になります。
設定管理ツール、テンプレート、バックアップ、変更管理は、システムの整合性を保つのに役立ちます。大きな変更の後は、フェイルオーバー準備状態を再確認します。
フェイルオーバーを定期的にテストする
定期テストは、実際の条件でフェイルオーバーが動くかを確認します。検出時間、切り替え時間、データ整合性、アプリケーション動作、ユーザーアクセス、ログ、フェイルバック手順を確認します。
テストは文書化する必要があります。各テストでは、何を試したか、何が起きたか、何が失敗したか、どの改善が必要かを記録します。
フェイルオーバー後のフェイルバックと復旧
フェイルオーバーは復旧プロセスの一部にすぎません。主システムが修復された後、組織はサービスを戻すか、どのように戻すかを判断します。このプロセスをフェイルバックと呼びます。
いつフェイルバックするか
フェイルバックは急ぎすぎてはいけません。元の主システムは、完全に修復、テスト、同期、確認された後でトラフィックを戻す必要があります。急いで戻すと、再度故障して別の中断を生む可能性があります。
一部の組織は、次の保守時間までバックアップシステムをアクティブのままにします。これにより、即時切り替えではなく制御された復帰ができます。
データと状態の同期
フェイルバック前に、バックアップ運用中に作成されたデータを元の主システムへ同期する必要があります。これは、データベース、ファイル、取引、ユーザーセッション、設定変更で特に重要です。
適切な同期がないと、フェイルバックはデータ損失、古い記録、不整合なサービス動作を引き起こす可能性があります。
インシデント後のレビュー
フェイルオーバー後、チームは発生した内容をレビューする必要があります。レビューには、障害原因、検出時間、切り替え結果、ユーザー影響、バックアップ性能、連絡プロセス、改善策を含めます。
これにより、フェイルオーバーは一度限りの復旧イベントではなく、信頼性を継続的に改善するプロセスになります。
FAQ
フェイルオーバーとは何ですか?
フェイルオーバーは、故障した主コンポーネントからバックアップコンポーネントへ、サービス、トラフィック、ワークロード、処理を切り替える信頼性の仕組みです。停止時間を減らし、サービス継続性を維持するために使われます。
フェイルオーバーとバックアップの違いは何ですか?
バックアップは、復旧のためにデータや設定を保存します。フェイルオーバーは、障害時に稼働中のサービスを別資源へ切り替えます。バックアップは情報復元を助け、フェイルオーバーはサービス継続を助けます。
アクティブ・パッシブフェイルオーバーとは何ですか?
アクティブ・パッシブ方式は、1つのアクティブシステムと1つの待機システムを使います。待機システムは、アクティブシステムが故障するか保守で停止したときだけ引き継ぎます。
アクティブ・アクティブフェイルオーバーとは何ですか?
アクティブ・アクティブ方式では、複数のシステムが同時にトラフィックを処理します。1つが故障しても、残りがユーザーを継続して処理し追加負荷を引き受けます。
フェイルオーバーはどこでよく使われますか?
企業ネットワーク、クラウドプラットフォーム、データセンター、データベース、Webアプリケーション、VoIPシステム、ファイアウォール、ルーター、ストレージ、産業制御プラットフォームでよく使われます。
フェイルオーバーはどのようにテストできますか?
主システム障害のシミュレーション、ネットワーク経路の制御された切断、テストノード停止、保守用フェイルオーバーの実行、サービス切り替え確認、データ整合性確認、復旧後のログ確認によってテストできます。







