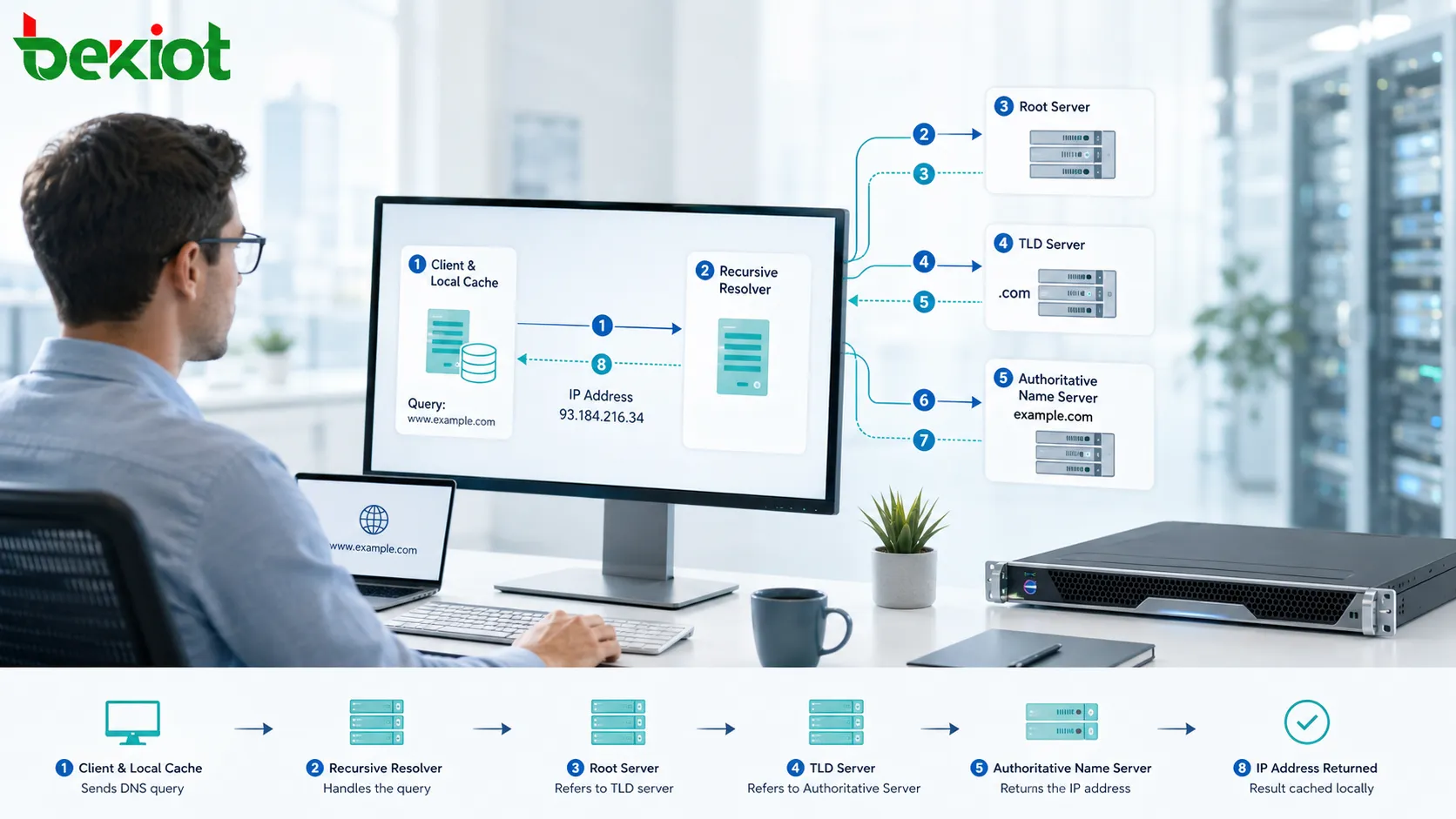
稼働率とは、システム・サービス・機器・アプリケーション・ネットワーク・プラットフォームが、利用可能な稼働状態を継続している時間のことを指します。簡単に言うと、対象が中断なく正常に動作している時間を示す指標です。Webサイトに問題なくアクセスできる状態、サーバーが安定起動している状態、コミュニケーションプラットフォームがオンラインで利用できる状態、ネットワーク機器が正常に動作し続けている状態など、本来の機能を果たしている期間が稼働時間としてカウントされます。
稼働率は、IT・ネットワーク・通信・クラウドサービス・産業用システム・Webサイト・データセンター・セキュリティプラットフォーム・業務用コミュニケーション環境などの分野で、最も重要な信頼性指標の1つです。企業が日々の業務を支えるのに十分なシステムの信頼性があるかを把握するのに役立ちます。稼働率が高いサービスはほとんどの時間利用可能であるのに対し、稼働率が低いサービスは頻繁な中断・停止・再起動・利用不可の時間が発生するリスクがあります。
実際の運用において、稼働率は単なる技術的な数値ではありません。顧客体験、事業継続性、サービスの評判、緊急時の対応力、生産性、運用に対する信頼にまで大きく影響します。必要な時にシステムが利用できなければ、どれだけ高性能な機能を搭載していても実用的な価値が失われてしまいます。そのため、稼働率はモニタリング、冗長化、保守計画、サービスレベルアグリーメント、災害復旧と合わせて議論されることが多いのです。
稼働率(Uptime)とは
定義と核心的な意味
稼働率とは、システムやサービスが正常に機能し、利用可能な状態が続いている期間のことです。対象はサーバー、ルーター、スイッチ、Webサイト、アプリケーション、データベース、クラウドプラットフォーム、IP PBX、セキュリティシステム、産業用コントローラーなど、ユーザーが依存するあらゆる接続機器が含まれます。システムに正常にアクセスでき、想定通りに動作している状態が「稼働中」と判断されます。
稼働率の核心的な意味は、「時間経過に伴う可用性」にあります。単に機器の電源が入っていることを意味するわけではありません。サーバーの電源が入っていてもユーザーからのリクエストに応答できない状態、ネットワーク機器が起動していてもトラフィックを正常に転送できない状態、Webサイトが一部表示されても主要な機能が動作しない状態などは、実務上の稼働時間としてカウントされません。実用的な稼働率の計測では、システムが本来の目的とするサービスを提供できる状態であることが必須となります。
このため、稼働率はシステムの実際の利用目的に沿って定義する必要があります。Webサイトの稼働率チェックではページの応答性を重視し、通信サービスでは登録処理、シグナリング、通話の完了率を重視し、データベースプラットフォームではクエリの応答性を重視するように、対象ごとに判断基準を設定することが重要です。
稼働率は単に機器の電源が入っているかどうかではなく、ユーザーが必要とする時に、想定したサービスが実際に利用できるかどうかを示す指標です。
稼働率と可用性の違い
稼働率と可用性は密接に関連しており、日常的な議論ではほぼ同じ意味で使われることも少なくありません。ただし、一般的に可用性はより広範なサービス指標として扱われます。稼働率が「システムが稼働し続けている時間」を示すのに対し、可用性は「実際の利用環境でユーザーが必要な機能を利用できるかどうか」までを含む概念です。
例えば、サーバーのプロセス自体は起動していても、ネットワークの問題でユーザーがアクセスできない場合、サービスの可用性は失われた状態となります。この場合、サーバー自体の稼働率は維持されていても、ユーザーから見たサービスの完全な可用性は確保できていないのです。複数のコンポーネントが連携して動作する複雑なシステムでは、この違いが非常に重要になります。
実際のサービス管理において、企業が最も重視するのはユーザーが実感する可用性です。機器のローカルのステータス画面だけでなく、ユーザーの視点から見てサービスが正常に動作することが求められます。

稼働率の仕組み
稼働時間の計測の仕組み
稼働率は、対象のシステムが正常かつ利用可能な状態を維持している時間の長さを計測することで機能します。計測の起点は、システムの起動時間、サービスの開始時間、モニタリングの応答時間、または定義されたサービス提供時間枠など、計測対象や企業が「稼働中」と定義する基準によって異なります。
単体の機器の場合、稼働率は前回の再起動からの経過時間として表示されることがあります。Webサイトの場合、外部からのプローブによってサイトが正常に応答するかどうかで稼働率を計測するのが一般的です。ネットワークサービスの場合、ユーザーが接続・認証・データの送受信・想定したトランザクションを完了できるかどうかまでが、稼働率の判断基準となります。
最も実用的な稼働率の計測は、サービスの実際の動作に紐付けられています。技術的には起動していても、主要な機能が正常に動作していないシステムは、厳密な運用モデルでは完全に利用可能な状態とはカウントされません。
ダウンタイムと可用性率の追跡
稼働率は、1ヶ月や1年といった定められた期間における「可用性率」としてパーセンテージで表記されるのが一般的です。基本的な計算式は、計測期間の総時間に対して、システムが利用可能だった時間の割合を算出するものです。期間のほとんどでサービスが利用可能だった場合は稼働率の数値が高くなり、長時間の停止が発生した場合は数値が低下します。
例えば、1ヶ月間で99.9%の稼働率を達成したサービスは、99%の稼働率のサービスよりもダウンタイムが短くなります。これらの数値は一見近いように見えますが、実際のダウンタイムの差は非常に大きくなります。業務運用、顧客アクセス、重要な通信を支えるシステムでは、わずかなパーセンテージの差が大きな影響を及ぼすのです。
このため、稼働率はサービスレベルアグリーメント(SLA)で頻繁に用いられます。プロバイダーは特定の稼働率を保証し、顧客はその保証内容からサービスの期待される信頼性を把握することができます。
稼働率のパーセンテージは一見シンプルですが、わずかな数値の差が、実際のダウンタイムの長さには大きな違いを生み出します。
一般的な稼働率のレベルとその意味
99%・99.9%・99.99%の稼働率の違いを理解する
稼働率は「ナイン(9)の数」で議論されることが多い指標です。99%の稼働率のシステムはほとんどの時間利用可能ですが、1年間では一定のダウンタイムが許容されることになります。99.9%の稼働率のシステムはより高い信頼性を持ち、許容されるダウンタイムが大幅に短くなります。99.99%の稼働率のシステムは非常に高い水準の信頼性が求められ、強固なシステム設計、モニタリング体制、運用ルールが必須となります。
目標とする稼働率が高くなるほど、達成の難易度は飛躍的に上がります。99%から99.9%への向上には、適切なモニタリングと保守体制の強化が必要になるのに対し、99.9%から99.99%への向上には、冗長化、フェイルオーバー、高可用性アーキテクチャ、厳格な変更管理、迅速なインシデント対応体制などが必要になります。
実際のシステム計画では、「見栄えが良いから」という理由だけで高い稼働率目標を設定するべきではありません。事業リスク、コスト、ユーザーの期待、業務上の重要性に合わせて、適切な目標を設定することが重要です。
稼働率が高いほどコストがかかる理由
高い稼働率を実現するには、一般的に多くの投資が必要になります。冗長化のない単体のサーバーは導入が容易でコストも抑えられますが、明確な障害ポイントが存在します。高可用性を実現するシステムでは、予備サーバー、冗長電源、複数のネットワーク経路、ロードバランサー、フェイルオーバー対応のデータベース、モニタリングツール、熟練した運用スタッフなどが必要になります。
コストはハードウェアだけに留まりません。システム設計、障害試験、保守手順の整備、スタッフのトレーニング、ソフトウェアアーキテクチャ、インシデント対応体制、場合によっては地理的な冗長化まで、多岐にわたります。レジリエンスを高めるためのレイヤーを追加するごとに、システムの複雑性も増加することになります。
このため、稼働率は単なるマーケティングの訴求ポイントではなく、システム設計の要件として扱うべきです。求められる信頼性の水準は、実際のアーキテクチャと運用プロセスによって裏付けられている必要があります。

稼働率に影響を与える主な要因
ハードウェアの信頼性と電源の安定性
ハードウェアの信頼性は、稼働率に影響を与える最も基礎的な要因の1つです。サーバー、ストレージ機器、スイッチ、ルーター、電源ユニット、ファン、ディスクなどの物理コンポーネントは、いずれも故障する可能性があります。バックアップ経路のない重要なコンポーネントが故障した場合、サービスの停止につながる恐れがあります。
電源の安定性も同じくらい重要です。どれだけ堅牢なシステムでも、電源が中断したり不安定になったりすると、正常に動作できなくなります。データセンターや重要な施設では、無停電電源装置(UPS)、予備発電機、二重化された電源供給路、電源モニタリングなどを導入し、このリスクを低減しています。
小規模な環境でも、信頼性の高い電源保護装置の導入や、機器の適切な保守といった簡単な改善で、稼働率を大幅に向上させることができます。
ネットワーク接続性とルーティングの安定性
多くのサービスはローカルネットワーク、広域ネットワーク、インターネットを経由してユーザーに提供されるため、ネットワーク接続性は稼働率に大きな影響を与えます。サーバー自体は正常に動作していても、ネットワーク経路に障害が発生すれば、ユーザーはサービスを利用できなくなり、ダウンタイムを経験することになります。スイッチの故障、ルーティングの設定ミス、DNSの障害、ファイアウォールの設定不備、ISPの回線停止など、いずれもサービスの可用性に影響を及ぼす要因となります。
冗長化されたネットワーク回線、複数のプロバイダーの利用、適切なルーティング設計、正しいDNS管理、継続的なモニタリングは、稼働率の向上に役立ちます。特に業務用コミュニケーションシステムでは、音声通話、ビデオ会議、メッセージング、クラウドアプリケーションがいずれも安定した接続性に依存するため、ネットワークの安定性は非常に重要です。
実務的には、稼働率はメインの機器だけでなく、サービス提供の全経路を通じて計測するべきです。
稼働率とシステムアーキテクチャ
冗長化とフェイルオーバー
冗長化は、稼働率を向上させるための最も一般的なアーキテクチャの手法です。現用系のコンポーネントに障害が発生した際に、即座に引き継げる予備のコンポーネントや経路を用意しておくことを指します。対象には、サーバー、電源ユニット、ディスク、スイッチ、ネットワーク回線、データベース、ゲートウェイ、データセンターなどが含まれます。
フェイルオーバーとは、障害が発生したコンポーネントから予備のコンポーネントへ、サービスの提供を切り替えるプロセスのことです。適切に設計されたシステムでは、フェイルオーバーは自動的に実行され、ユーザーの中断はほとんどまたは全く発生しません。単純なシステムでは、手動での切り替えが必要になる場合もあります。
冗長化とフェイルオーバーは、すべてのリスクを完全になくすわけではありませんが、1つの障害がシステム全体の停止につながる可能性を大幅に低減します。ダウンタイムが事業や安全に大きな影響を与えるシステムでは、必須の設計要素となります。
ロードバランシングと高可用性設計
ロードバランシングも、トラフィックを複数のサーバーやサービスインスタンスに分散させることで、稼働率の向上に貢献します。1台のサーバーが過負荷になったり障害が発生したりしても、他のサーバーがリクエストの処理を継続できるため、適切に導入することでパフォーマンスとレジリエンスの両方を向上させることができます。
高可用性設計は、冗長化、フェイルオーバー、クラスタリング、レプリケーション、ヘルスチェック、自動復旧、モニタリングなど、複数の技術を組み合わせて実現します。個々のコンポーネントに障害が発生した場合でも、サービスの提供を継続することを最終的な目標としています。
高可用性システムは、綿密な試験が必須です。冗長化されたコンポーネントは、実際に障害が発生した際に正しく引き継ぎを行えてこそ、意味のあるものになります。
稼働率は願望ではなく、アーキテクチャによって構築されるものです。信頼性の高いシステムには、障害が発生する前に設計・試験された障害対応の経路が必要不可欠です。
稼働率のモニタリング
内部モニタリングと外部モニタリング
稼働率のモニタリングとは、対象のシステムやサービスが利用可能な状態かどうかを継続的に確認する取り組みのことです。内部モニタリングは、サーバーのCPU・メモリ・ディスクの状態、プロセスの稼働状況、データベースの状態、ローカルネットワークの接続性など、環境の内部からコンポーネントの状態を監視する手法です。外部モニタリングは、ユーザーの視点に近い環境の外部から、サービスの可用性を確認する手法です。
どちらの手法もそれぞれ有用な役割を持っています。内部モニタリングは、ユーザーに影響が及ぶ前に障害の予兆を検知することができます。外部モニタリングは、サービスが外部から実際にアクセス可能かどうかを確認することができます。内部からは正常に見えるシステムでも、DNS、ルーティング、ファイアウォール、上流ネットワークの問題で、外部からはアクセスできない状態になっていることがあるためです。
堅牢なモニタリング戦略では、内部と外部の両方のチェックを組み合わせることで、稼働率の全体像を把握することが一般的です。
ヘルスチェック、アラート、インシデント対応
ヘルスチェックとは、システムが想定通りに動作しているかどうかを確認する自動化された試験のことです。単純なチェックではサーバーがリクエストに応答するかどうかを確認するのに対し、高度なチェックではログイン処理、データベースの応答、通話の登録処理、トランザクションの完了、APIの動作など、実際のサービスの動作までを検証します。
アラートは、稼働率が危険にさらされたり、ダウンタイムが発生したりした際に、管理者に通知する仕組みです。ただし、アラートを設定するだけでは十分ではありません。企業は、誰が調査を行うか、問題をどのようにエスカレーションするか、ユーザーにどのように情報を提供するか、サービスをどのように復旧するかを定めたインシデント対応プロセスを整備する必要があります。
モニタリングは、検知と対応を連携させてこそ最大の価値を発揮します。ダウンタイムを早期に把握できても、チームが効果的に対応できなければ意味がないのです。
稼働率とSLA
サービスレベルアグリーメント(SLA)
サービスレベルアグリーメント(一般的にSLAと呼ばれます)には、サービスプロバイダーまたは社内の運用チームが提供を保証する稼働率の数値が定められることが多いです。例えば、プロバイダーが「月額の課金期間において99.9%の稼働率を保証する」と約束するケースが代表的です。SLAには、何をダウンタイムと定義するか、どのような保守時間帯が除外されるか、目標を達成できなかった場合の補償やクレジットの内容なども明記されます。
稼働率の解釈は定義によって大きく異なるため、SLAの文言は非常に重要です。一部の契約では計画的な保守時間がダウンタイムから除外されたり、サービスの完全な停止のみをダウンタイムとしてカウントし、部分的なパフォーマンスの低下は含めなかったり、顧客の所在地からではなくプロバイダーのネットワーク内からの可用性を計測基準としたりするケースがあります。
このため、サービスを利用する側はSLAの定義を注意深く確認する必要があります。公表されている稼働率の数値も重要ですが、その計測ルールも同じくらい重要なのです。
計画保守と計画外ダウンタイム
計画保守とは、システムの可用性に一時的に影響を与える可能性のある事前にスケジュールされた作業のことです。ファームウェアのアップグレード、ソフトウェアの更新、ハードウェアの交換、データベースの保守、セキュリティパッチの適用、インフラの構成変更などが含まれます。多くの稼働率の計算では、計画保守は予期せぬ障害による停止とは区別して扱われます。
計画外ダウンタイムとは、ハードウェアの故障、ソフトウェアのクラッシュ、ネットワークの停止、設定ミス、サイバー攻撃、電源の喪失、ヒューマンエラーなどによって、システムが予期せず停止してしまうことです。ユーザーが事前に準備できないため、このタイプのダウンタイムは一般的に事業への影響がより大きくなります。
適切な稼働率管理では、計画外ダウンタイムを最小限に抑えるとともに、計画保守のスケジュールを事前に明確に通知し、ユーザーが準備できるようにすることが重要です。
稼働率を向上させるための保守のポイント
予防保守の実施
予防保守は、障害が発生して停止に至る前に問題に対処することで、稼働率の向上に貢献します。具体的には、ログの確認、ファームウェアの更新、セキュリティパッチの適用、経年劣化したハードウェアの交換、ストレージ容量の監視、バックアップの動作試験、システムのパフォーマンス傾向の分析などが含まれます。
予防保守は、スケジュールを定めて実施し、作業内容を記録することが重要です。場当たり的な設定変更は新たな問題を引き起こす可能性がありますが、管理された保守作業はリスクを低減することができます。予防保守の目標は、不要な中断を引き起こすことなく、システムを健全な状態に維持することです。
実際の運用において、多くのシステム停止は、警告の兆候が障害に発展する前に保守チームが対処できていれば防げたものが少なくありません。
変更管理の徹底
設定変更は、ダウンタイムの一般的な原因の1つです。ファイアウォールのルール設定、ルーティングの変更、ソフトウェアの更新、証明書の交換、データベースの調整、アクセスポリシーの変更などは、適切なレビューを行わないと、誤ってサービスを停止させてしまう可能性があります。変更管理を徹底することで、このリスクを低減することができます。
適切な変更管理には、作業内容の文書化、承認プロセス、事前試験、ロールバック計画、実施時間の選定、変更後の動作確認が含まれます。重要なシステムの変更は、業務への影響が少ない時間帯に実施し、作業後は綿密にモニタリングを行うべきです。
稼働率は、堅牢なハードウェアと同じくらい、規律正しい運用に依存する部分が大きいのです。
多くの稼働率の問題は、機器の故障から始まるのではなく、管理されていない変更、不十分な保守習慣、動作確認の欠落から始まります。
稼働率計測の活用シーン
Webサイト・クラウドサービス・アプリケーション
Webサイト、クラウドサービス、アプリケーションの分野では、ユーザーが必要な時にデジタルサービスにアクセスできるかどうかを評価するために稼働率の計測が活用されます。Eコマースサイト、SaaSプラットフォーム、オンラインバンキングシステム、顧客向けポータル、ストリーミングプラットフォーム、業務用アプリケーションなどは、いずれも高い可用性に依存しています。
これらの環境では、ダウンタイムは売上の損失、顧客の不満、ブランドイメージの毀損、社内業務の中断につながります。稼働率をモニタリングすることで、企業は問題を早期に検知し、サービスのパフォーマンスがユーザーの期待に応えられているかを評価することができます。
顧客向けのサービスにおいて、稼働率は信頼性を示す最も可視化された指標の1つとなることが多いのです。
ネットワーク・通信システム・インフラストラクチャ
稼働率は、ネットワークや通信システムの分野でも極めて重要です。ルーター、スイッチ、ファイアウォール、IP PBXプラットフォーム、SIPサーバー、ゲートウェイ、指令システム、インターコムネットワーク、セキュリティシステム、監視プラットフォームなどは、いずれも安定した動作が必須となります。これらのシステムに障害が発生すると、音声通話、データアクセス、アラーム通知、入退室管理、業務の連携調整などに影響が及びます。
インフラストラクチャの稼働率は、他の多くのサービスがその上に依存しているため、特に重要性が高くなります。クラウドアプリケーション自体は正常に動作していても、ローカルネットワークに障害が発生すればユーザーはアクセスできません。通信プラットフォーム自体は起動していても、ゲートウェイや中継経路に障害が発生すれば通話が完了できなくなります。
このため、インフラストラクチャの稼働率は、物理的な機器からユーザー向けのサービスまで、複数のレイヤーでモニタリングを行うのが一般的です。
ダウンタイムの主な原因
技術的な障害
技術的な障害には、ハードウェアの故障、ソフトウェアのクラッシュ、メモリリーク、データベースの不具合、ディスクの故障、ネットワーク機器の障害、電源の中断、冷却システムの不具合、リソースの枯渇などが含まれます。これらは多くの環境でダウンタイムの一般的な原因となっています。
技術的な障害の中には、突然発生するものもあれば、徐々に進行するものもあります。ディスクは故障する前に警告サインを示すことがあり、サーバーはクラッシュする前に動作が遅くなることがあり、ネットワーク回線は完全に停止する前にパケットロスが発生することがあります。モニタリングを行うことでこれらの早期の兆候を検知し、チームが事前に対処することが可能になります。
冗長化、アラート、キャパシティプランニング、予防保守は、いずれも技術的な障害の影響を低減するのに役立ちます。
ヒューマンエラーとプロセスの不備
ヒューマンエラーも、ダウンタイムの大きな原因の1つです。誤ったコマンドの実行、データの誤削除、ファイアウォールルールの設定ミス、不適切なファームウェアファイルの適用、有効期限切れの証明書、十分に試験されていない更新プログラムの適用などは、いずれもサービスの停止を引き起こす可能性があります。多くのケースで、ハードウェアの性能が低いからシステムが停止するのではなく、運用プロセスが不十分なことが原因となっています。
プロセスの管理を徹底することで、このリスクを低減することができます。作業内容の文書化、アクセス権の管理、ピアレビュー、変更承認プロセス、バックアップ、ステージング環境の整備、ロールバック計画は、ヒューマンエラーが発生した場合の影響を最小限に抑えます。管理者がシステムの仕様だけでなく、設定変更がもたらす影響を理解するために、トレーニングも重要な要素となります。
堅牢な稼働率管理では、人、プロセス、テクノロジーを一体の信頼性システムとして扱う必要があります。
稼働率を向上させる方法
障害を前提とした設計
稼働率の向上は、障害を前提とした設計から始まります。すべてのコンポーネントは、いつかは故障する可能性があります。信頼性の高いシステムは、障害が発生することを前提として、予備の経路、モニタリング体制、復旧手順、試験済みのフェイルオーバーの動作をあらかじめ組み込んでおくのです。
このアプローチは、設計のマインドセットを根本的に変えます。「コンポーネントが故障するかどうか」を問うのではなく、「故障した場合に何が起こるか」を問うようになるのです。もし答えが「サービス全体が停止する」であれば、設計に改善の余地があります。答えが「トラフィックが予備の経路に自動的に切り替わり、ユーザーは作業を継続できる」であれば、よりレジリエンスの高いシステムであると言えます。
障害を前提とした設計は、高い稼働率を実現するためのコアプリンシプルの1つです。
ユーザーが実際に体験する可用性の計測
稼働率の改善に取り組む際には、内部のステータスだけでなく、ユーザー体験に焦点を当てるべきです。サーバーのダッシュボード上でプロセスが起動しているように見えても、実際にはユーザーがログインできない、通話ができない、ファイルを開けない、トランザクションを完了できないといった状況が発生している可能性があります。そのため、モニタリングには可能な限りエンドツーエンドのサービスチェックを含めるべきです。
ユーザー視点の計測を行うことで、コンポーネント単位のチェックでは見落としてしまう問題を明らかにすることができます。また、ダウンタイムが事業に与える実際の影響を把握するのにも役立ちます。ユーザーがサービスの本来のタスクを完了できないのであれば、ユーザーの視点からはシステムは真に利用可能な状態ではないのです。
優れた稼働率管理のプログラムは、技術的な健全性と、ユーザーが実際に体験するサービスの動作の両方を計測するものです。
まとめ
稼働率とは、システム・機器・サービス・プラットフォームが、利用可能な稼働状態を維持している時間を計測する指標です。Webサイト、クラウドプラットフォーム、ネットワーク、通信システム、データセンター、産業用インフラ、業務用アプリケーションなどの分野で、信頼性を示す重要な指標として活用されています。高い稼働率を維持することで、ユーザーは必要な時にサービスを利用できるという信頼を得ることができます。
稼働率は、計測期間内のサービスの利用可能時間と総時間を比較することで算出されます。ハードウェアの信頼性、ネットワークの接続性、電源の安定性、ソフトウェアの品質、システムアーキテクチャ、モニタリング体制、保守運用、運用ルールなど、多くの要因が稼働率に影響を与えます。高い稼働率を安定的に実現するには、一般的に冗長化、フェイルオーバー、予防保守、変更管理の徹底、実態に即したサービスモニタリングが必要になります。
実務的には、稼働率は単なるパーセンテージの数値ではありません。実際のユーザーと事業のニーズを支えるために、システムがどれだけ適切に設計、運用、モニタリング、保守されているかを反映する指標なのです。
よくある質問
稼働率とは簡単に言うとどういう意味ですか?
簡単に言うと、稼働率とはシステムやサービスが正常に動作し、利用可能な状態が続いている時間のことです。Webサイト、サーバー、ネットワーク、機器が問題なく動作している期間が、稼働時間としてカウントされます。
一般的には、システムの信頼性を測るために用いられる指標です。
稼働率はどのように計算されますか?
稼働率は一般的に、定められた計測期間の総時間に対して、システムが利用可能だった時間の割合を算出することで求められます。算出結果は、99.9%のようにパーセンテージで表記されるのが一般的です。
正確な計算方法は、「利用可能な状態」「ダウンタイム」をどのように定義するかによって異なります。
稼働率はなぜ重要ですか?
稼働率が重要なのは、ユーザーや企業は必要な時にシステムが利用できることを前提に業務を進めているためです。稼働率が低いと、生産性の低下、通信の失敗、顧客の不満、サービスの中断、売上の損失などにつながる恐れがあります。
高い稼働率は、システムの信頼性、事業の継続性、ユーザーの信頼を支える基盤となります。